防火墙CPU高
- 1收藏

描述
问题描述:
防火墙运行过程中出现CPU高的情况。
解决方法:
1、检查配置是否规范
配置相关引起CPU高的方面挺多,例如:未开策略加速、基于域名的安全策略、基于http的aspf检测、端口块过小、syslog配置、NAT配置过多导致流表资源不足、开启不需要的NAT ALG导致关联表数量过大等都会导致设备CPU利用率升高。
① 查看是否开启了策略加速功能
可以通过如下命令查看包过滤策略是否开启加速。
命令:display acl all
例如:通过命令查看acl 3333开启了加速。

针对对象策略,通过如下命令查看对象策略test没有开启加速。

说明:对于M9000而言,R9131P26及之后版本对象策略默认开启了加速,包过滤策略没有开启加速。所以,如果版本在R9131P26之前,需要在对象策略和包过滤策略中手动开启加速功能,如果版本在R9131P26及之后,只需要在包过滤策略中手工开启加速即可。
安全策略加速是默认开启的,且不能手动关闭,如下几种情况会导致安全策略加速功能失效。
(1)激活安全策略规则加速功能时,内存资源不足会导致安全策略加速失效。
若安全策略规则中指定的IP地址对象组中包含排除地址和通配符掩码,则会导致安全策略加速功能失效。
(2)安全策略加速失效后,设备无法对报文进行快速匹配,但是仍然可以进行原始的慢速匹配。
(3)为使新增或修改的规则可以对报文进行匹配,必须激活这些规则的加速功能。
(4)激活安全策略规则的加速功能时比较消耗内存资源,不建议频繁激活加速功能。建议在所有安全策略规则配置和修改完成后,统一执行accelerate enhanced enable命令。
(5)若安全策略规则中指定的IP地址对象组中包含用户或用户组,则此条安全策略规则失效,将无法匹配任何报文。
(6)安全策略规则中引用对象的内容发生变化后,也需要重新激活该规则的加速功能。
例如,对象组中包含排除地址和通用符掩码会导致加速失败,新版本中会报如下日志:

可以通过命令开启策略加速功能。
命令:accelerate
例如:针对现场配置中的包过滤策略和对象策略,开启策略加速功能,增加策略的匹配效率,降低CPU利用率。

② 查看是否配置了基于域名的安全策略
设备上配置了基于域名的安全策略,设备首先会自动对以上域名进行DNS解析,返回的结果以动态缓存的方式存在于设备,安全策略会调用相应的地址进行策略匹配。如果个别条目的DNS老化时间很短的话,当老化时间结束后设备会再度进行请求,安全策略感知到DNS有记录更新后,会对安全策略重新进行加速,这个过程会导致流量重新匹配一次策略,走一次慢速转发,短时间大量耗费CPU的资源,导致ping报文会短暂有延时波动,没有其他影响。
可以通过如下命令进行查看域名解析结果,如有回显说明配置了基于域名的安全策略。
命令:display dns host
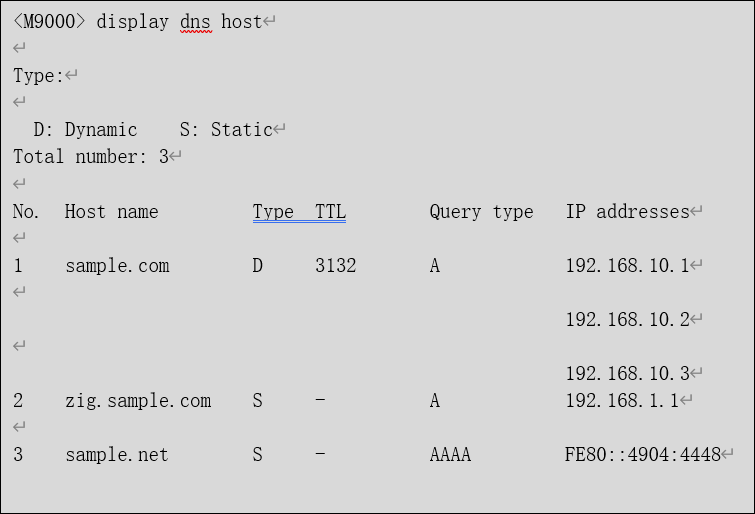
该波动感知极小,业务几乎无感知,也可以根据现网环境调整策略。
如果需要保持延时稳定,建议将设备上基于域名的对象策略更换为IP地址方式。如果需要在不影响业务的情况下操作,首先在有域名的地址对象中添加对应的IP地址对象,等待几分钟后,把域名对象删除即可。
③ 查看是否配置了基于HTTP的ASPF检测
由于ASPF策略对HTTP应用层协议报文进行内容检测,因此所有的HTTP协议报文都上送CPU处理,从而导致blade板CPU升高的现象。
可以通过如下命令查看配置基于http协议的aspf检测。

因为ASPF detect http 主要和是 URL 配合使用的,为URL提供HTTP协议的合法性检测和url的提取,所以一般业务场景下,不需要配置detect http命令,建议删除ASPF中的http检测配置。

④ 查看是否存在端口不足
防火墙常作为NAT出口设备,用于公私网地址转换,网络中经常使用私对公转换NAT444和私对私动态地址转换,如果网络中出现主备倒换,由于之前的会话要等自然老化,新建会话重新创建,一个地址的端口块为250,如果不够用,端口资源反复计算,会导致CPU高影响业务。等会话老化后,端口自然释放,老化的时间为3600s。重置会话就会释放端口资源,不会出现端口资源不足的情况,可以通过如下命令查看:
如果确认均为正常业务,且端口块不够用的情况下,需要扩大端口块范围,命令如下:

或者将静态nat444改为动态nat。
⑤ 查看是否syslog日志量过大
设备上的日志主要分为syslog日志和Flow日志,syslog日志又包含安全日志、应用审计日志、设备日志和快速日志;Flow日志包含nat日志和session日志,其用来记录NAT会话信息,主要包括用户访问网络的流的5元组信息(源IP地址、目的IP地址、源端口、目的端口、协议号),以及发送和接收的报文统计信息。Flow日志有两种输出方式,一种是将Flow日志封装成UDP报文直接发送给网络中的日志主机。日志主机可以对Flow日志进行解析和分类显示,以达到远程监控的目的;一种是将Flow日志输出到本设备的信息中心模块,再通过设置信息中心的输出参数,最终决定Flow日志的输出方向。通常情况下,用户访问网络会在短时间内产生大量NAT会话日志。系统日志传输格式为ASCII码,相比Flow日志的二进制格式传输效率低。所以,一般情况下,不建议使用输出到信息中心的方式。
如果设备上配置了域间策略日志,并且日志量较大,syslog会上送到info-center信息中心处理,当syslog日志量很高时,会导致cpu升高,造成主控控制通道拥塞,导致一些协议报文,比如ospf协商报文被丢弃,出现业务不通的问题。设备配置NAT/ATK/DPI LOG日志,在没有Userlog或Customlog配置的情况下,会默认以Syslog格式发送,发送性能低,会导致CPU高,内部通道拥塞,板卡重启等现象。
如果设备上配置了域间策略/NAT/ATK/DPI LOG日志,建议域间策略/NAT/ATK/DPI LOG采用customlog发送,NAT日志也可以采用userlog发送,快速日志输出功能主要用于快速地将用户关心的日志发往日志主机。配置该功能后,业务模块生成的日志通过快速输出通道直接发送给日志主机,不经过信息中心模块处理。相比通过信息中心输出,该方式可以节省系统资源,更快捷。设备支持通过快速日志输出、Flow日志和信息中心功能将某些业务模块的日志发送给日志主机,这些功能按优先级从高到低的顺序依次为快速日志输出、Flow日志、信息中心,对于同一业务模块,如果用户配置了高优先级的输出方式,则不再采用其他方式输出。将安全策略日志、深度报文检测日志、攻击防范日志通过快速日志方式输出,配置命令如下:
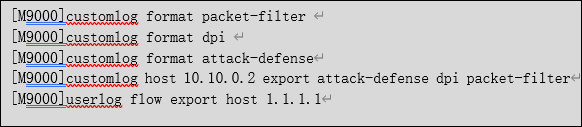
⑥ 查看关联表数量是否过大
对于多通道协议,ASPF除了创建会话表项之外,还会根据协议的协商情况,创建一个或多个关联表项,用于关联属于同一个应用业务的不同会话。关联表项在多通道协议协商的过程中创建,在多通道协议协商完成后删除。关联表项主要用于匹配会话首报文,使已通过协商的会话报文可免于接受静态包过滤策略的检查。
关联表的老化时间从父会话继承,当父会话有持续流量时,由于父会话不会老化,因此关联表也一直不老化,老化时间一直保持为300秒(udp-ready的默认老化时间)。以SIP为例,对应SIP会话中的报文会持续创建关联表,并且没有及时释放,导致了关联表累积。
针对一个父会话下挂大量关联表的情况,当前设备在备份关联表时存在性能瓶颈,因此会导致CPU持续高的情况,可以通过如下命令查看设备的关联表信息。
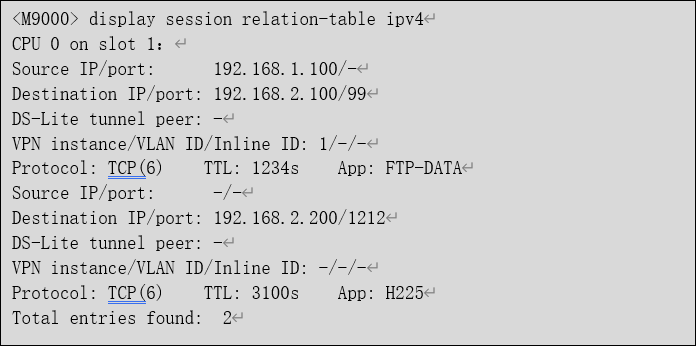
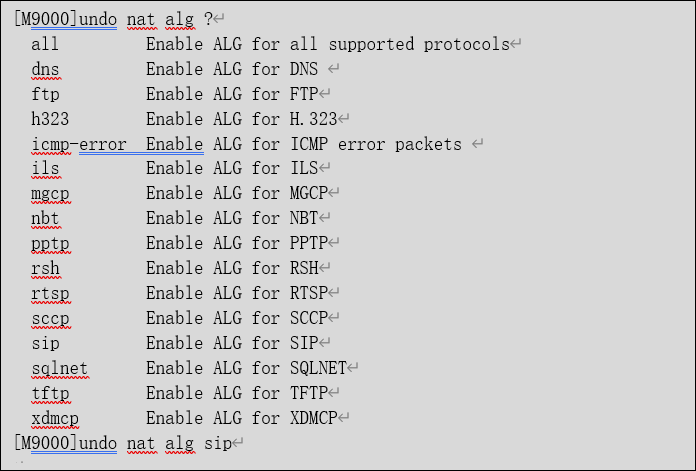
确认现场是否会用到关联表信息,清除设备的会话和关联表信息,查看是否有会话相关的关联表应用识别,同时通过抓包进行确认,在不需要ALG的情况下,业务是否正常,如果正常,则可以关闭ALG功能,以SIP为例,相关命令如下:
⑦ 查看是否流表资源不足
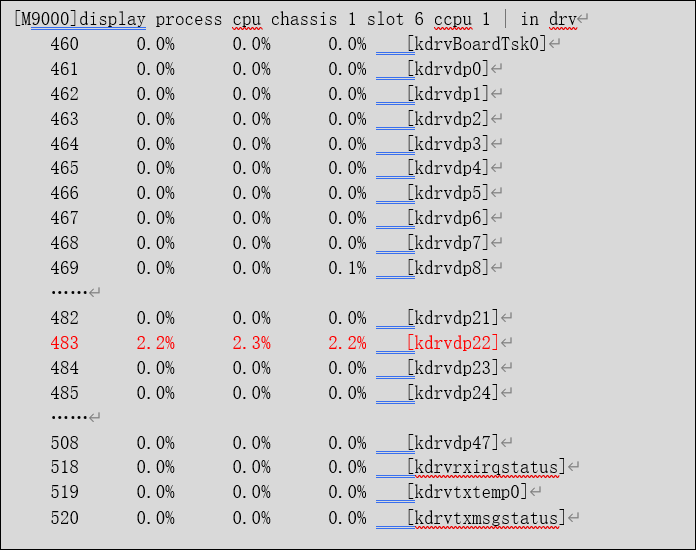
M9000的转发是基于流表进行的,如果流表资源不足的情况下,会出现各种问题。比如现场有虚墙业务,在引流资源不足的情况下,由于虚墙的引流是二次引流实现的,所以存在一次hash到一个blade 板卡,再二次引流到另一块blade板卡的现象。由于设备重启,所有的引流都是同时恢复,所以生效的引流无法控制,在此情况下,会出现大量的blade板间二次引流的情况,导致CPU单核被耗尽,类似于下图这种情况。
查看接口板qacl资源的命令如下所示,主要关注显示命令的最后一行,即free-ofp信息。
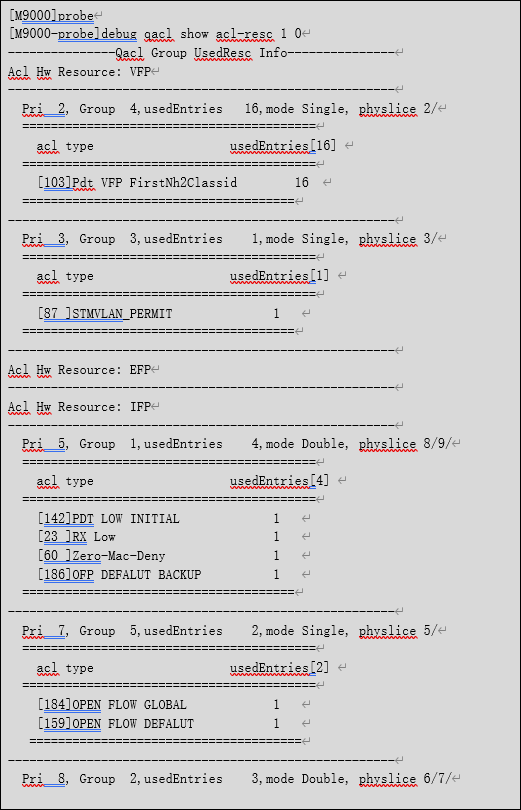
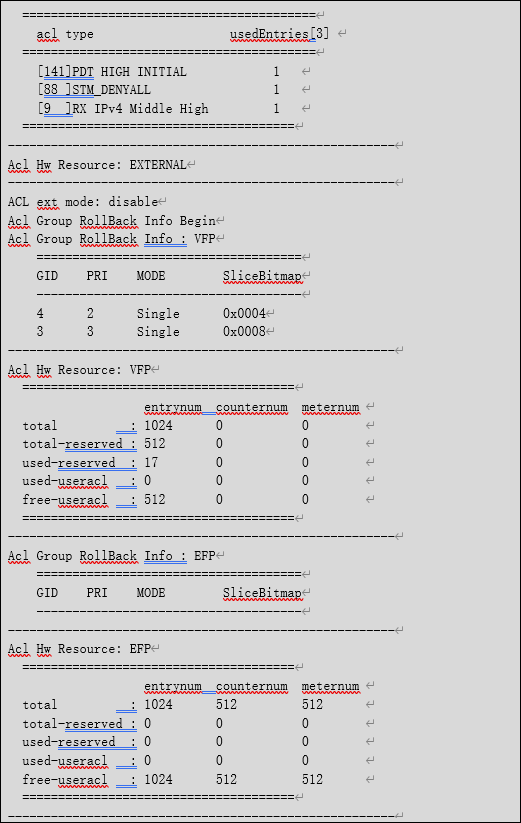
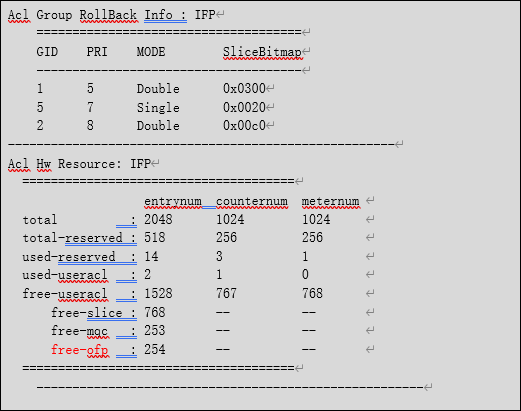
如果现网存在多余的nat配置,可以删除无用的nat配置,从而来减少qacl 资源的利用率;如果没有存在多余的配置,可以更换qacl资源更多的接口板或者更改方案。
2、优化相关配置
针对设备上不规范的配置,并且容易导致CPU利用率高的地方进行优化,比如,针对规则较多的策略开启策略加速;基于域名的安全策略改为IP地方方式;删除基于http的aspf检测;针对端口块不足的情况,扩大端口块;采用customlog格式发送策略日志、DPI日志和会话日志;针对流表不足的情况,优化NAT相关配置或者更换qacl资源更多的接口板,关闭不需要的ALG等。
3、查看是否存在单条流过大
所有V7的安全硬件设备(不包括-V这种部署在服务器上的虚拟设备),在运行流量转发、nat、LB、VPN、安全策略等功能时都需要消耗设备的CPU硬件资源,这就会导致大流量的情况下,CPU占用率较高。此时可以通过display cpu查看当前CPU整体占用率。
防火墙单CPU(盒子设备一般就一颗CPU,分布式设备一般一块板卡一颗CPU或一个子卡一颗CPU)目前在网的大部分型号都是非X86的,一颗CPU会虚拟出多个VCPU,俗称单核。流量上墙后如果要上CPU处理,默认的是根据源地址hash上到某一个单核处理,即源地址相同的流都上到同一个单核处理。
导致单核高的常见的有如下几种情况:
1)正常流量导致单核高;
2)攻击流量导致单核高;
3)环路导致单核高;
上述三种情况总结一句话就是某一条或几条流量非常大导致单核被占满。所以排查问题的主要思路就是找到影响单核的流量的三元组信息。然后根据三元组继续判断是否是异常流量,如果是异常流量,那么需要在上行设备配置阻断(防火墙上配置阻断需要消耗CPU算力,效果可能不明显),如果是正常流量在具体判断是否可以开启逐包转发等。
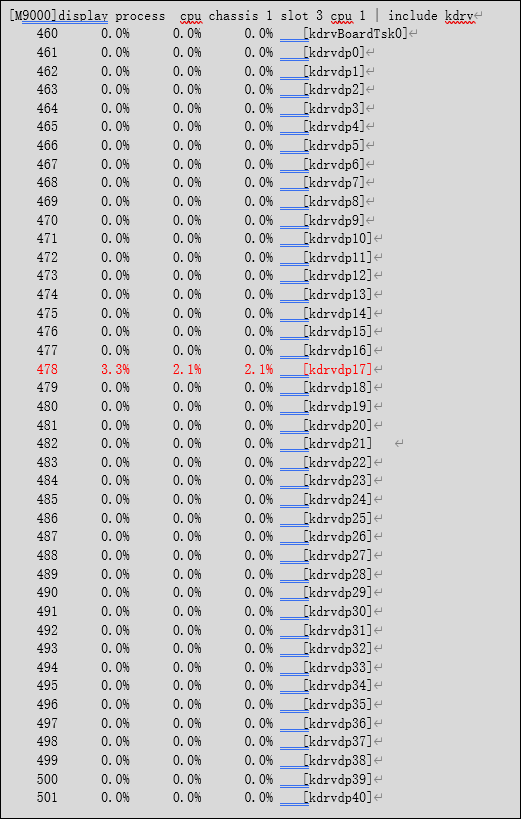
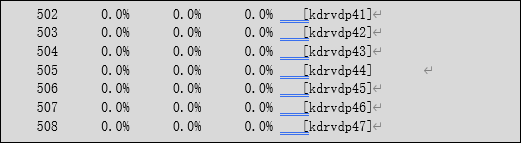
命令:display process cpu chassis X slot X cpu 1 | include kdrv
例如:如图所示1框3槽的业务板vcpu kdrvdp17已打满。
4、查看异常流量
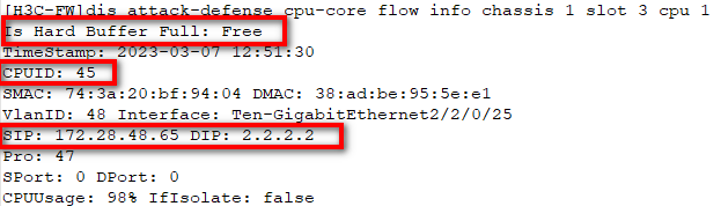
高端和中低端新版本都支持如下命令直接查看单核占用的记录,display attack-defense cpu-core flow info chassis X slot Y cpu 1 (X=框号,Y=槽位号)查看对应板卡处理的攻击流量。
老版本没有上述命令直接查看单核占满的记录,需要手工配置一个EAA脚本实现自动化监控。 举例如下:

5、阻断异常流量
如果确认该条流量的ip地址非业务地址,可以通过安全策略、黑名单或者qos策略进行阻断。如果确认单条流的业务为正常业务,需要修改为逐包转发,命令如下:

6、查看是否大量报文命中黑洞fib
设备上配置nat server之后会下发一条目的地址到global地址的黑洞路由,类似于如下配置:
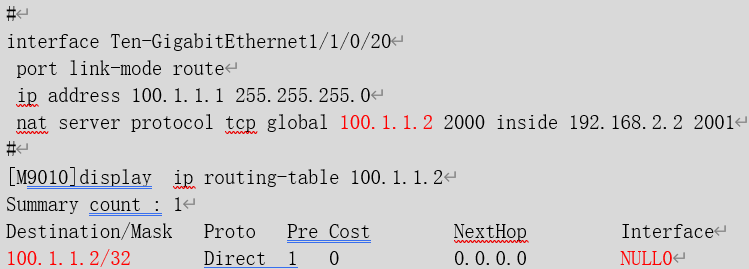
此时,如果有大量的流量访问100.1.1.2的非2000端口时,则该流量将会命中设备上的黑洞路由。
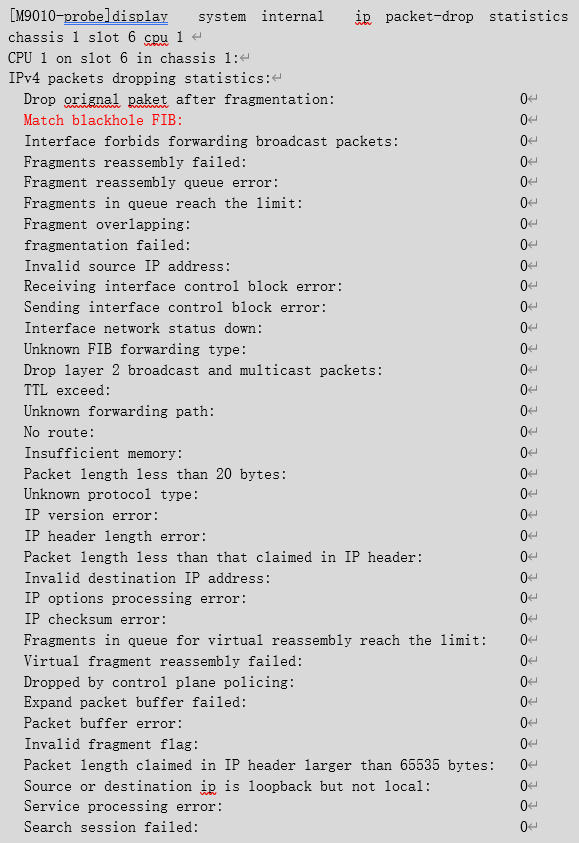
通过debug ip packet查看也可以看到流量命中FIB黑洞:
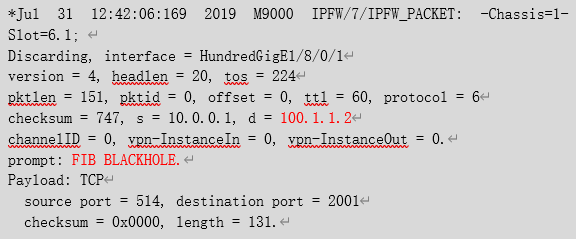
可见,接口下的映射关系为TCP的2000端口,但是通过debug ip packet看到是访问的TCP 2001端口,导致该报文命中黑洞路由被丢弃,大量的TCP目的端口为2001的报文冲击设备导致业务板CPU利用率异常升高,影响到正常的业务。
7、阻断命中黑洞的流量
通过debug已经可以看到哪些流量命中了黑洞路由,明确ip地址之后,在接口下发qos策略进行阻断使设备的CPU利用率恢复到正常值。


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作