某局点H3Cloud OS首页显示状态400错误
- 0关注
- 0收藏 1545浏览

组网及说明
略。
问题描述
某局点H3Cloud OS E3106H01 登录首页时显示状态400的错误,其中influxdb-nginx pod 处于CrashLoopBackOff状态,显示截图如下:

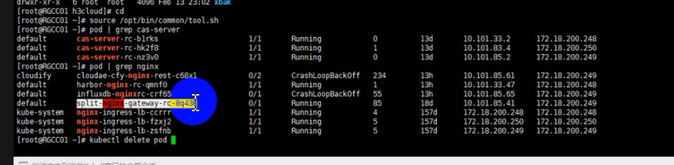
过程分析
经远程查看为现场一个node 节点的ntpd服务未启动导致与其他两个节点的时间不一致。时间不一致导致此节点的flanneld地址与docker的bip不一致,进而导致pod异常。远程查看的命令如下:
ansible all –m shell –a ‘cat /run/flannel/subnet.env && ps -ef | grep bip ’
解决方法
解决方法:
第一步: 开启异常节点的ntpd服务: systemctl start ntpd && systemctl enable ntpd
第二步: 慢慢等待时间同步,一般ntpd是慢慢的同步,可以等待他们慢慢同步时间。
第三步: 重启有异常pod,待所有pod都正常running之后问题解决。
注意:
遇到Cloud OS的问题,可以先从以下几方面检查:
[root@heccloud01 ~]# cat /run/flannel/subnet.env && ps -ef | grep bip
FLANNEL_NETWORK=10.101.0.0/16
FLANNEL_SUBNET=10.101.44.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=false
root 3323 1 32 May20 ? 2-17:47:24 /usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --insecure-registry=172.25.18.103:9999 --bip=10.101.44.1/24 --mtu=1500 --storage-driver=devicemapper --storage-opt dm.datadev=/dev/centos/data --storage-opt dm.metadatadev=/dev/centos/metadata --log-opt max-size=1g --log-opt max-file=2
root 32322 17022 0 17:14 pts/2 00:00:00 grep --color=auto bip
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作