cloudos2.0的rabbitmq存储卷占满的一种处理方法 (二)
- 0关注
- 0收藏 2344浏览

组网及说明
不涉及
问题描述
cloudos2.0的1139H06及之前版本存在一个已知问题:rabbitmp存储卷中保存的消息队列的信息不能及时删除导致rabbitmq的存储卷占满100%的情况。 前台表现:界面上执行任务卡住(如新建中、重启中、删除中等任务卡住的情况),严重的会导致cloudos的前台界面无法登陆。

过程分析
cloudos2.0的1139H06及之前版本存在一个已知问题:rabbitmp存储卷中保存的消息队列的信息不能及时删除导致rabbitmq的存储卷占满100%的情况。后台表现:在rabbitmq卷的如下路径下有多17M大小的rdq的文件,导致该卷占满。

解决方法
1、临时解决
A、先进行查看环境中前台其他的pod是否是running的,如不是,请及时处理;
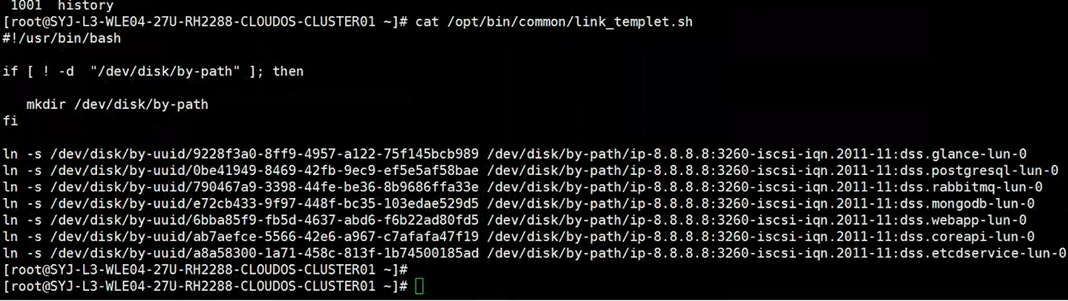
B、命令cat /opt/bin/common/link_templet.sh看一下,是否是以uuid的方式挂载的。如下截图的查看结果是以uuid的方式挂载的。
C、如果cat /opt/bin/common/link_templet.sh的查看结果不是以uuid挂载的,df -h看一下,记录一下rabbitmq卷的挂载点,如下截图

D、使用/opt/bin/kubectl -s 127.0.0.1:8888 scale --replicas=0 rc rabbitmqrc命令,将rabbitmq的 pod置0,暂停这个pod。
E、如果是uuid方式挂载的,使用如下命令将rabbitmq的卷格式化: mkfs.ext4 /dev/disk/by-uuid/790467a9-3398-44fe-be36-8b9686ffa33e(步骤B中,查到的rabbitmq挂载卷的uuid)
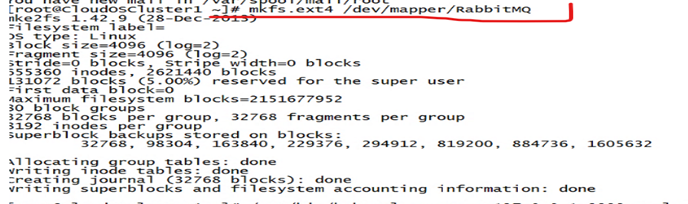
F、如果是py-path的方式挂载的,使用如下命令将rabbitmq的卷格式化: mkfs.ext4 /dev/mapper/RabbitMQ(步C中查到的rabbitmq挂载的路径),具体如下截图。
G、使用/opt/bin/kubectl -s 127.0.0.1:8888 scale --replicas=1 rc rabbitmqrc命令,将rabbitmq的 pod置1,启动这个pod。
H、等大概2分钟,等rabbitmq的pod起来之后,/opt/bin/kubectl --server=127.0.0.1:8888 get pod -o wide命令看一下,所有的pod是否都是runnning的。
I、 重新检查cloudos相关功能是否恢复。
2、彻底解决
CloudOS E1139H07版本增加了及时删除rabbitmq队列消息的策略,可以升级至该版本。

编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作