某局点U-Center2.0手动恢复和修改trap定义不定期失败
- 0关注
- 0收藏 1218浏览

组网及说明
无特殊组网,U-Center2.0版本为PLAT E0610+IOM E0608L02
问题描述
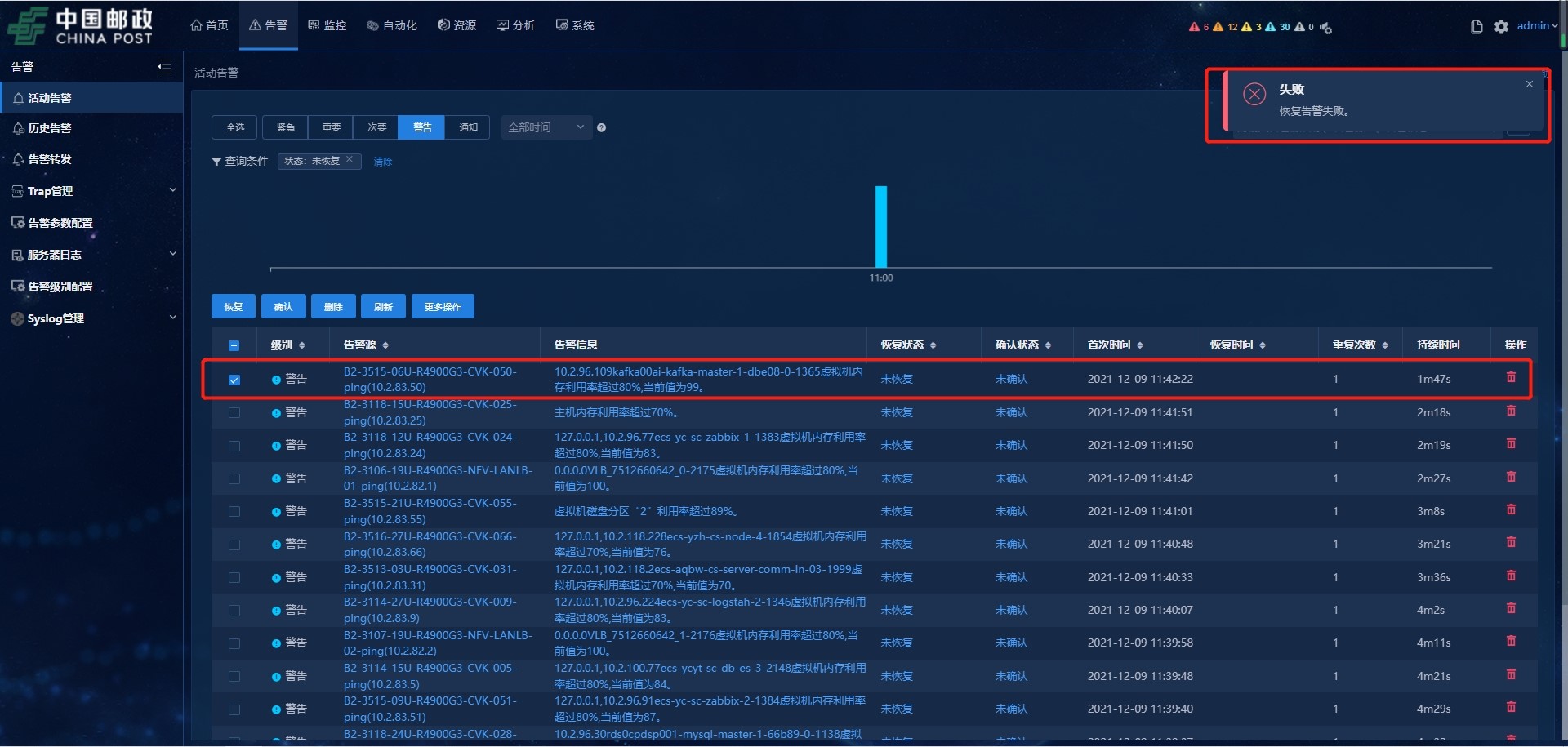
1、告警恢复操作,页面经常提示“恢复告警失败”。刷新页面查看,查看此告警可能已恢复了,也可能并没有恢复。
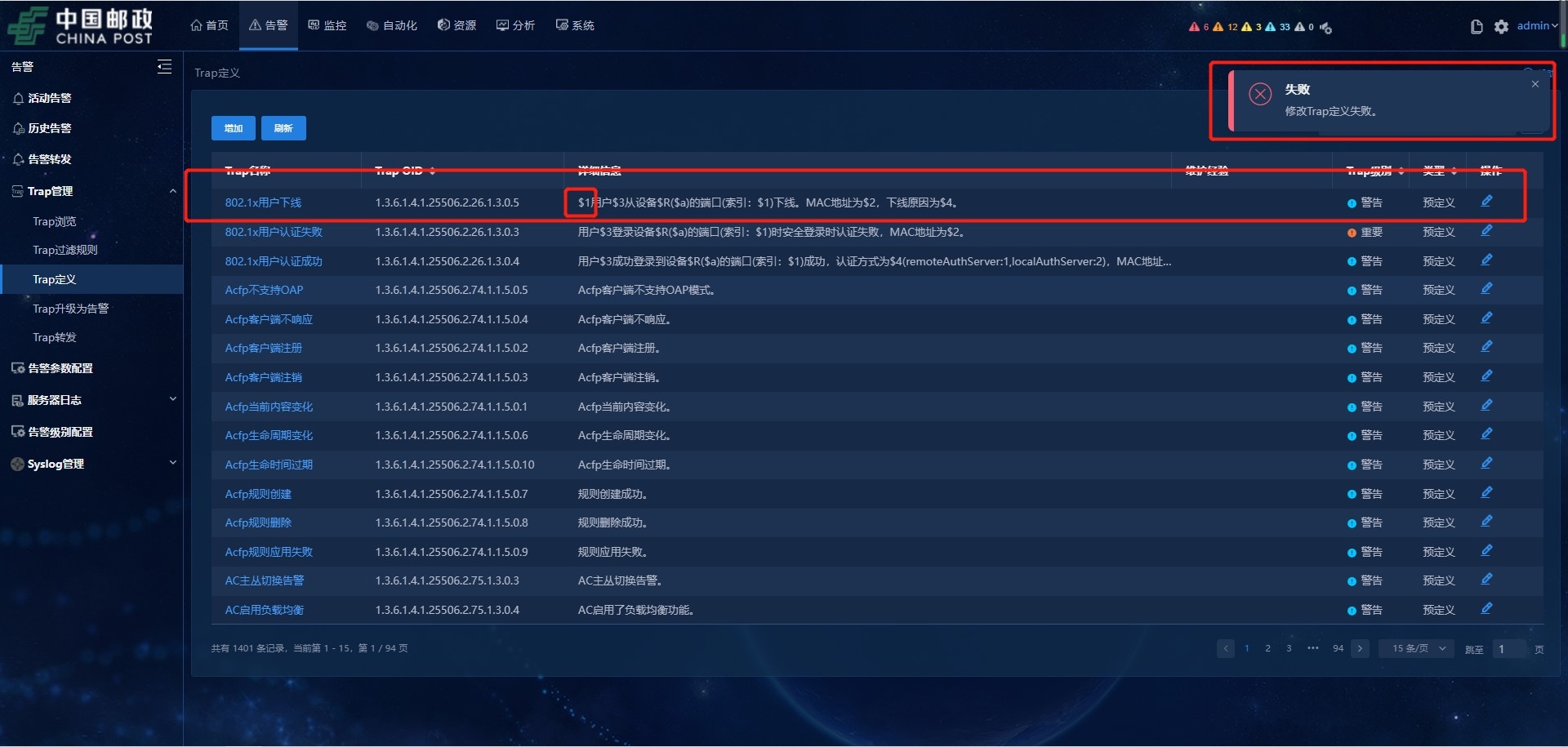
2、修改trap定义也是不定期提示修改失败。刷新页面查看trap定义可能已经修改成功,也可能还是未修改的状态
过程分析
现场告警相关pod都是正常运行状态
itom-alarm-dm-7ffcf8bf85-q6qsx 1/1 Running 0 102m
itom-alarm-rs-84d6f4597b-lpm6h 2/2 Running 0 155d
itom-alarm-ui-685ccb9f7f-bm7ff 1/1 Running 0 155d
复现问题后收集itom-alarm-dm日志分析发现
1、告警恢复操作两次,均有收到前台消息,但后台日志均显示操作成功;
2、 三次修改Trap的操作,后台只收到了1次消息,日志显示操作成功
据此,怀疑是前台与消息中间件kakfa的连接出问题,有时不能将消息发送到kafka,或者不能收到后台回复的消息。
因为现场是E0610版本,这个版本确实存在pod与kafka因为某种原因(例如pod重启,网络故障)断开连接之后,概率性的发生kafka不能重连的问题。这个问题已经通过修改kafka的配置进行过优化,合入的版本是E0612,以及E07的各个发布版本。
若要临时规避,可依次尝试下列操作:
1、
删除alarm-rs的pod,使其重启
kubectl get pod -n service-software|grep itom-alarm-rs
执行上述命令,记下NAME
kubectl delete pod [NAME] -n service-software
重启完成后,观察功能是否恢复,如未恢复,则继续执行下面第二步
2、
删除alarm-dm的pod,使其重启
kubectl get pod -n service-software|grep itom-alarm-dm
执行上述命令,记下NAME
kubectl delete pod [NAME] -n service-software
重启完成后,观察功能是否恢复,如未恢复,则继续执行下面第三步
3、
kubectl scale deployment kafka-0 kafka-1 kafka-2 -n service-software --replicas=0
在集群所有点上,均执行rm -rf /var/lib/ssdata/kafka,清除脏数据
kubectl scale deployment kafka-0 kafka-1 kafka-2 -n service-software --replicas=1
执行完成后,按照第1、2步的说明,重启alarm-rs和alarm-dm的pod
解决方法
若要彻底解决此问题,建议升级U-Center2.0至E0612及其后续版本
若要临时规避,可依次尝试下列操作:
1、
删除alarm-rs的pod,使其重启
kubectl get pod -n service-software|grep itom-alarm-rs
执行上述命令,记下NAME
kubectl delete pod [NAME] -n service-software
重启完成后,观察功能是否恢复,如未恢复,则继续执行下面第二步
2、
删除alarm-dm的pod,使其重启
kubectl get pod -n service-software|grep itom-alarm-dm
执行上述命令,记下NAME
kubectl delete pod [NAME] -n service-software
重启完成后,观察功能是否恢复,如未恢复,则继续执行下面第三步
3、
kubectl scale deployment kafka-0 kafka-1 kafka-2 -n service-software --replicas=0
在集群所有点上,均执行rm -rf /var/lib/ssdata/kafka,清除脏数据
kubectl scale deployment kafka-0 kafka-1 kafka-2 -n service-software --replicas=1
执行完成后,按照第1、2步的说明,重启alarm-rs和alarm-dm的pod,最后刷新页面尝试再次恢复告警或修改trap定义
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作