拓步发生变更!!
- 0关注
- 1收藏,4549浏览

问题描述:
满屏报文的是一台华三的监控汇聚交换机,汇聚交换机上接了五六台监控接入交换机,其中有一台8口poe监控接入交换机上接入两个海康摄像头,到接入交换机距离15米左右。这两个海康摄像头一天出现好几次掉线,掉线时间5.6分钟。什么原因,摄像头,网线,都换过,问题不能解决。怀疑是交换机问题
组网及组网描述:
满屏报文的是一台华三的监控汇聚交换机,汇聚交换机上接了五六台监控接入交换机,其中有一台8口poe监控接入交换机上接入两个海康摄像头,到接入交换机距离15米左右。这两个海康摄像头一天出现好几次掉线,掉线时间5.6分钟。什么原因,摄像头,网线,都换过,问题不能解决。怀疑是交换机问题
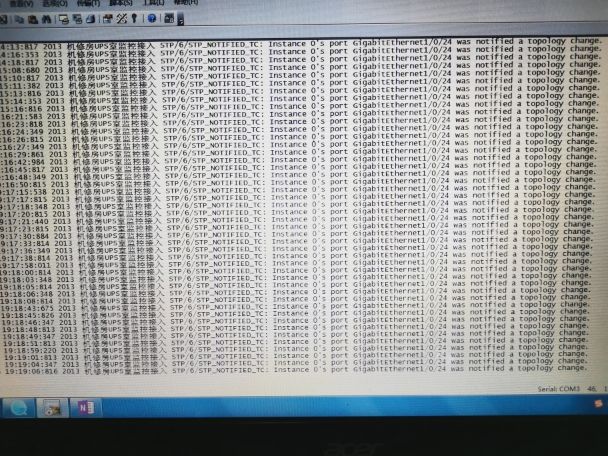
- 2021-08-02提问
- 举报
-
(0)




频繁收到TC报文,STP一直在计算和收敛,这期间是不转发数据的。
以下是排查要点,请参考:
1、检查物理链路是否有问题。
2、终端接入的端口开启STP边缘端口。
3、如果对端网络设备无法管理到,可开启STP TC保护。
4、根桥的下联端口开启STP根保护。
- 2021-08-02回答
- 评论(0)
- 举报
-
(0)
暂无评论


TC(网络拓扑变化)报文太多了,每产生一次拓扑变化就会导致交换机刷新一次mac地址表,所以会丢包,解决方法就是把交换机所有连接终端的端口设置成边缘端口。命令如下:
[HEXIN-S7500E-X-GigabitEthernet1/0/0/32]stp edged-port
TC报文是什么
小伙伴们在日常维护中是否发现,交换机上可能经常产生STP TC报文的日志告警,比如:
TC报文对现网业务的影响可大可小,有时仅仅体现为偶尔出现告警打印,有时却能引起报文泛洪、拥塞丢包。因此为了网络的正常稳定运行,应该尽可能消除异常TC报文的产生。那TC报文到底是什么呢?
我们常说的TC报文其实就是TCN BPDU,它的作用是网络中的其他网桥通知根桥网络拓扑发生了变化。上面的告警中出现了两种TC报文,一种是STP_DETECTED_TC,这是接口所在生成树实例或VLAN拓扑发生变化,本端设备检测到拓扑变化后产生的TC报文。另一种是STP_NOTIFIED_TC,这是远端相连设备通知本设备某接口所在生成树实例或VLAN的拓扑发生变化后产生的TC报文。
什么情况下
会产生TC报文
按照IEEE协议规定,TCN BPDU的产生条件有两个:
1. 网桥上有端口转变为Forwarding状态,且该网桥至少包含一个指定端口。
2.网桥上有端口从Forwarding状态或Learning状态转变为Blocking状态。
若上述两个条件之一满足,就说明网络拓扑发生了变化,网桥就需要使用TCN BPDU通知根桥这一变化。在日常维护中,TC报文的产生通常有以下几种情况:
1. 设备或链路出现故障,引发STP重新计算,产生TC报文。
2. STP配置参数更改,引发STP重新计算,产生TC报文。
3. 连接终端的端口使能了STP,但没有配置为边缘端口,当终端发生重启等情况导致该端口链路状态变化时,该端口产生TC报文。
4. 来自用户设备的攻击TC报文也可能传入其所接入的二层网络。
收到TC报文会怎样
H3C系列交换机上实现的是标准MSTP的STP兼容模式,接口收到TC报文后,将把所有VLAN或Instance实例中所有VLAN的MAC表项删除,由流量触发重新学习,ARP表项会由设备会主动发送ARP请求报文来进行更新。
下面我们通过一个小实验来说明该过程。
一、实验拓扑
在Spine和Leaf上共起四个网关地址,使用一台交换机来模拟PC,配置四个VLAN虚接口模拟四个终端设备。
除PC外的其他设备均开启MSTP,Access-2与PC互联接口配置边缘端口和BPDU保护功能。
通过手动打开和关闭Access-1的上行接口来模拟网络中的链路故障和新接入交换机,构造拓扑改变触发条件。
二、网络初始状态
Spine为根设备,初始TC收发为0,正常学习到55.1.1.2和66.1.1.2的ARP表项。
Leaf设备上初始TC收发为0,正常学习到77.1.1.2和88.1.1.2的ARP表项。
接下来通过手工关闭一次再打开一次Access-1的上行口,来模拟网络中互联接口UP/DOWN和新接入交换机的场景,在整个过程中观察以下三方面情况:
1. 观察各设备的TC报文收发情况。
2. PC和网关之间不进行互ping操作,观察Spine和Leaf的ARP表项老化时间的更新情况。
3. 在Access-2上行口抓包,观察网络中ARP报文的传递过程。
三、TC报文收发情况
1. Spine设备上
手工关闭一次再打开一次Access-1的上行口后,可以看到Spine打印了两条TC告警。这是因为Access-1的上行接口DOWN再UP一次时,Access-1和Leaf上都有非边缘端口转为Forwarding状态,满足TC报文产生的条件,所以Access-1和Leaf各会产生一个TC报文然后泛洪到Spine上。
通过display stp tc命令查看TC报文的收发计数,也可以看到Spine收到2个TC报文。
2. Leaf设备上
可以看到Leaf上打印两条TC告警,其中一个TC报文是Leaf自身端口震荡产生的,另一个TC报文是Access-1端口震荡后产生并泛洪发给Leaf的。
这里需要注意是,如果是设备自身端口震荡产生的TC报文,日志中的关键字是DETECTED,如果是收到其他设备泛洪过来的TC报文,日志中关键字是NOTIFIED。
四、ARP表项更新情况
1. Spine设备上
初始ARP表项在1091S后将老化,Access-1接口UP后,Spine收到泛洪过来的TC报文,触发ARP表项更新,ARP表项的默认老化时间为1200S,变为1181S说明刚刚学习更新。
2. Leaf设备上
初始ARP表项在750S后将老化,Access-1接口UP后,Leaf收到泛洪过来的TC报文,触发ARP表项更新,ARP表项的默认老化时间为1200S,变为1176S说明刚刚学习更新。
五、抓包观察ARP报文收发情况
在Access-2上行口抓包,可以看到在接口UP后,Spine和Leaf均发出了ARP请求报文去更新自己设备上的ARP表项。
六、小节
1. 非边缘端口出现UP/DOWN时设备会产生STP TC报文,并会通过根端口和非边缘端口往其他设备发送TC报文,从而导致TC报文的整网泛洪。
2. 收到TC报文的设备会触发MAC和ARP表项的刷新,MAC表项被删除后由流量触发重新学习,ARP表项由设备主动发起ARP请求报文更新。
TC报文的
排查和优化
交换机偶尔出现少量STP TC日志告警可以不必过分关注,但在规模较大的二层网络域中,若交换机频繁收到TC报文,则会频繁刷新MAC地址表,可能造成短暂的未知单播流量泛洪,拥塞丢包;频繁刷新ARP表可能造成网络中瞬时出现大量ARP协议报文,导致核心设备CPU利用率升高,影响其他协议报文的处理。
因此我们应该尽可能消除频繁产生的TC报文,主要可以按照以下几点进行排查和优化:
1. 首先尽量从源头消除TC报文,找到是哪台设备的接口在频繁震荡。执行命令diplay stp tc查看频繁收到TC报文的端口,如果某端口收到的TC报文一直递增,查看该端口的对端设备的TC接收端口,一级一级往下直到找到TC源。
2. 根据上一步的排查结果,再继续定位接口震荡的原因。如果是设备间的互联接口,建议做一些硬件替换测试消除接口震荡。如果是互联终端的接口则建议配置STP边缘端口和BPDU保护功能。
3. 对于某些不便排查源头的网络,可以在端口上配置stp tc-restriction命令来开启TC-BPDU传播限制功能,此后当该端口收到TC-BPDU时,不会再向其他端口传播。
4. 在我司设备网络和其他厂商设备网络的交界处,如果只有单条路径连接,可以在该链路所连端口上配置stp disable或者bpdu drop。如果存在多条路径,则对其异常收TC情况进行监控和检查。
5. 尽可能合理规划和控制二层网络域的规模,当二层网络域规模较大,汇聚、接入和终端设备数量较多时,建议在核心和汇聚设备之间关闭STP功能,使每台汇聚设备与其下联网络构成一棵单独的STP树,每颗树之间互不影响,从而减小TC报文的泛洪和影响范围。
- 2021-08-02回答
- 评论(0)
- 举报
-
(1)
暂无评论
编辑答案


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作
举报
×
侵犯我的权益
×
侵犯了我企业的权益
×
- 1. 您举报的内容是什么?(请在邮件中列出您举报的内容和链接地址)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
- 3. 是哪家企业?(营业执照,单位登记证明等证件)
- 4. 您与该企业的关系是?(您是企业法人或被授权人,需提供企业委托授权书)
抄袭了我的内容
×
原文链接或出处
诽谤我
×
- 1. 您举报的内容以及侵犯了您什么权益?(请在邮件中列出您举报的内容、链接地址,并给出简短的说明)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
对根叔社区有害的内容
×
不规范转载
×
举报说明
暂无评论