某局点统一数字底盘heketi pod状态为CrashLoopBackOff的经验案例
- 0关注
- 0收藏 1139浏览

问题描述
在统一数字底盘后台执行kubectl get pod -A -owide | grep -v Run命令,发现heketi pod的状态为CrashLoopBackOff,如下图所示:

继续执行kubectl logs -f heketi-xxx(heketi pod名称)-n glusterfs-example命令,发现提示“数据库文件不存在”的错误,如下图所示:

过程分析
先执行kubectl get pod -A | grep gluster命令获取gluster pod名称,再执行kubectl exec -it gluster-xxx(gluster pod名称) -n glusterfs-example bash命令登录任一gluster pod后台,接着执行gluster volume heal heketidbstorage info命令可以看到heketi.db处于”Is in split-brain“状态(即脑裂状态)。如下图所示:
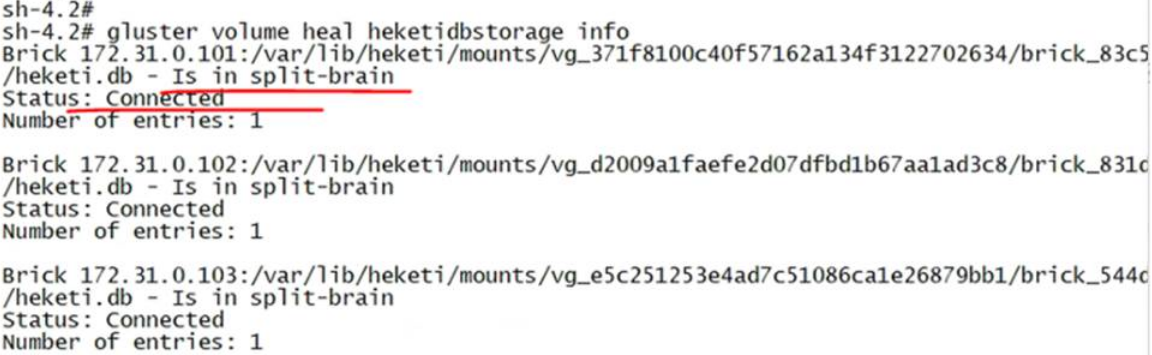
当统一数字底盘的版本是E0613P08(不含)之前版本时,在出现服务器下电或者网络波动的情况下heketidbstorage存储卷概率出现脑裂,会导致heketi数据库异常。
解决方法
(1)临时规避方案:登录任一gluster pod后台执行gluster volume heal heketidbstorage split-brain latest-mtime /heketi.db命令进行修复。修复后再执行gluster volume heal heketidbstorage info命令,可以看到如下正常回显:
(2)彻底解决方案:升级统一数字底盘至E0613P08(含)及以后版本。
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作