
组网及说明
告警信息
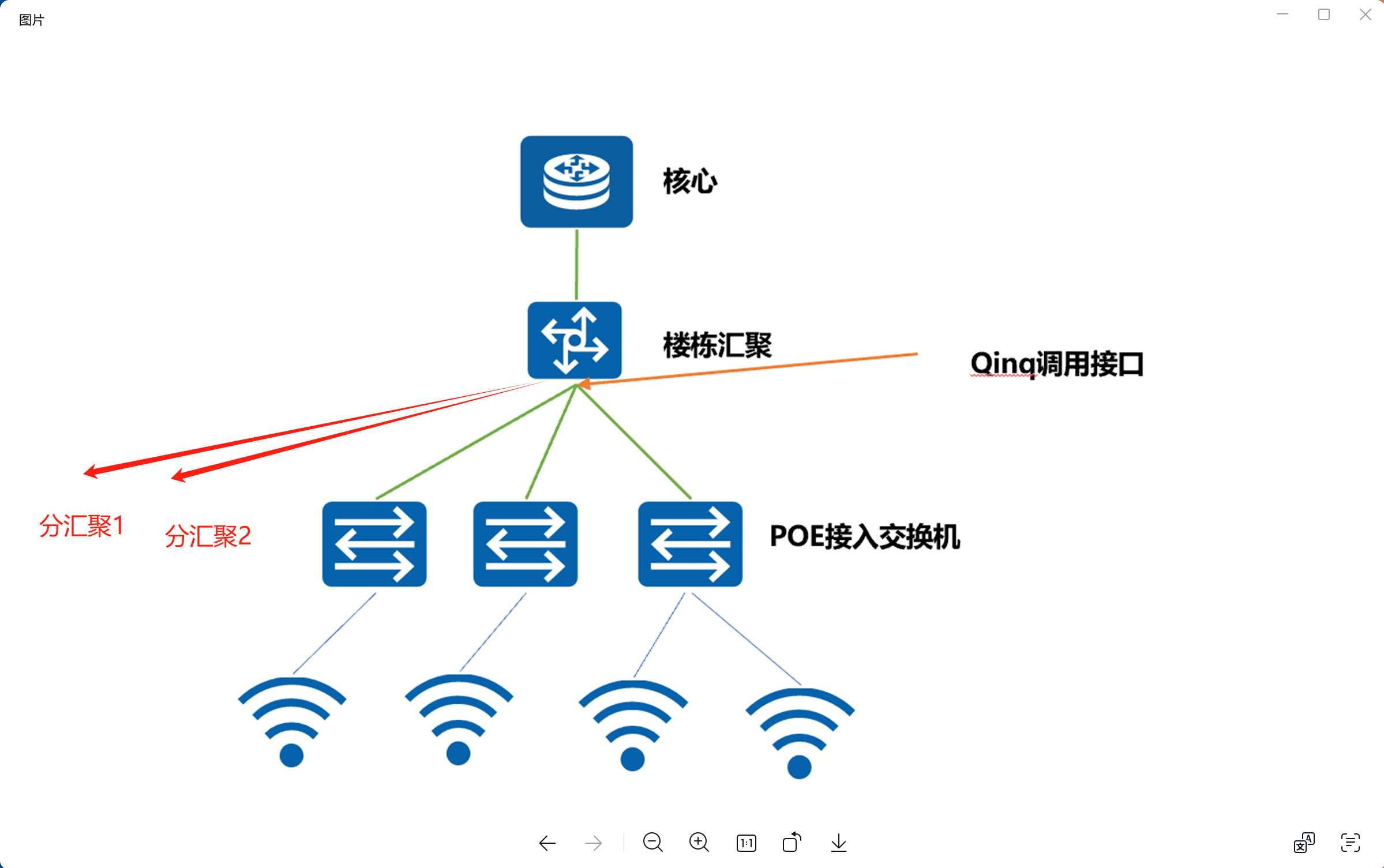
传统组网,AC旁挂核心,以汇聚交换机下行口为临界点,分为外层vlan和内层vlan,AP管理地址外层vlan为1298,内层vlan为298,通过核心交换机给AP下发vlan1298的地址。
问题描述
客户有两栋楼新建了无线业务,对应两台汇聚交换机A和B,业务上线后发现两栋楼里面的AP不定时的会掉线,并且自己能重新上线,现象一天能复现三四次,相对比较频繁。
过程分析
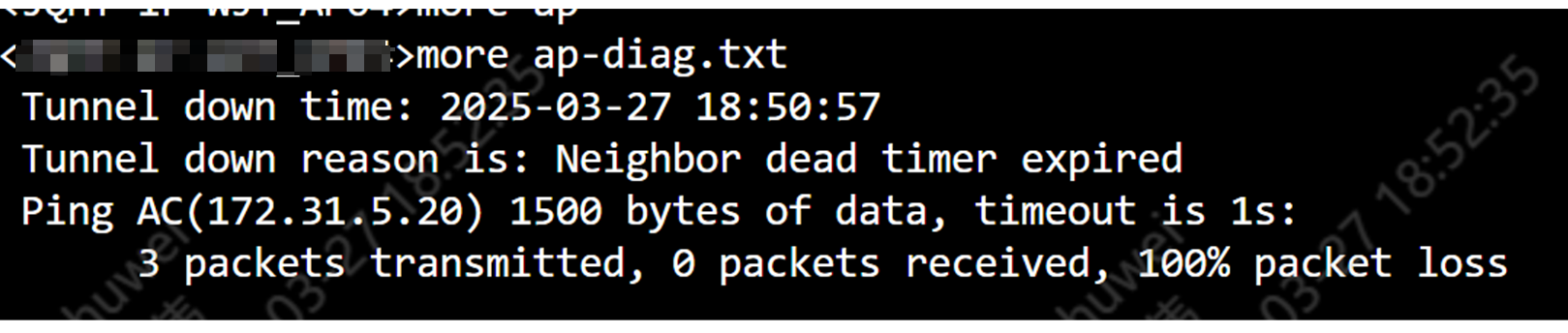
1,看AC和AP诊断,没有看到设备上的异常,查看AP掉线原因,都是Processed join request in Run state 和Failed to retransmit message。看见这两个异常下线原因就有理由怀疑是链路问题导致。随即查看ap上的ap-diag文件,果然有丢包记录。
2,由此判定为链路问题,就让客户去排查物理链路了,客户那边排查了两天也没发现物理链路问题,客户试过很多方法都不行,AP该掉线还是掉线。但是前方反馈是因为汇聚配置了qinq之后才出现的,前方工程师把其中的B汇聚qinq配置删除掉,然后对比了一下两个汇聚下的AP状态,经过两天的运行,B汇聚下AP都是稳定在线,没有掉线情况,A汇聚还是和之前一样,随机不定时的掉线。
3,经过上面的排查确定了是qinq的配置导致,于是找了对应交换机产线,交换这边明确表示qinq配置不会导致链路问题,数据怎么来的经过交换机就怎么出去,无非就是添加和删除外层vlan,打上外层vlan的标签数据包的大小会增加4。到这又没有思路继续了。
4,看ap-diag的内容,显示大包不通,经过测试发现,ping测试报文大小超过1468就不通,这会不会就是导致AP掉线的原因呢?通过分析AP上行口交换机镜像抓包分析,AP是否在线由capwap的管理帧决定,即使是数据帧不通,AP也不会掉线。多次抓包显示AP在线的时候,对应维持AP在线的保活报文大小不超过100字节,也就排除了这个问题。由此发现ap-diag的内容实际参考意义不大,前面排查问题思路就搞错了。
5,最后在早上九点左右问题高发的时间段,在汇聚交换机的上行口和下行口分别抓包分析。在抓包时间段,有AP掉线,随即就分析掉线前的保活报文。

在这可以看到AC回复的Response报文带的外层vlan标签为1,内层vlan普通抓包看不到。对比正常的报文,外层vlan标签应为1298。到此终于找到问题的根因了,交换机侧表示收到的数据是什么就转发什么,现在就是要分析核心交换机为什么会把标签改为1发给汇聚交换机了,由于核心交换机是友商设备,后面就由友商去排查这个vlan标签的问题了。
解决方法
最终友商给的结论为有未知源主机中毒,病毒主机频繁扫描AP的9100等其他端口,扫描动作触发了友商设备的代码bug,导致核心交换机回复给AP的内层VLAN ID置为0,转发给汇聚时内层标签置为1,使AP和AC的保活报文超时,导致AP掉线。
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作