(修订)HPE Synergy 480 Gen11 Compute Module - 连接到Mezzanine slot 1 或 slot 3 的融合网卡可能会出现吞吐量低的情况
- 0关注
- 0收藏 970浏览

组网及说明
文档ID:a00131243en_us Last Updated: 2025-03-07
影响范围:任何配置了融合网络适配器的HPE Synergy 480 Gen11 计算模块
问题描述
对于任何 HPE Synergy 480 Gen11 计算模块,连接到Mezzanine slot 1 或 slot 3的任何融合网卡都可能会遇到低吞吐量。
此问题出现在与 CPU 1 关联的Mezzanine slot 1 或 slot 3 上,原因是两个 CPU之间的 I/O 负载不平衡。与 CPU 2 关联的Mezzanine slot 2 不会出现此问题。
过程分析
N/A
解决方法
要避免此问题或如果此问题已经发生,请执行以下步骤:
1. 按F9 进入System Utilities
2. 选择"System Configuration" > "BIOS/Platform Configuration (RBSU)"
3. 选择"Workload Profile"
4. 设置工作负载"Virtualization Max Performance"
5. 按F12保存退出
6. 重启计算模块并启动进系统
7. 将 NUMA 节点映射调整为如下所示的值。步骤取决于操作系统。
|
Device |
NUMA Node |
|
Mezzanine1 Port1 |
3 |
|
Mezzanine1 Port2 |
3 |
|
Mezzanine2 Port1 |
7 |
|
Mezzanine2 Port2 |
6 |
|
Mezzanine3 Port1 |
2 |
|
Mezzanine3 Port2 |
2 |
For Linux
运行命令"numactl --interleave=all <customer application>"。您可以在下方链接中找到更多信息。
For VMware vSphere
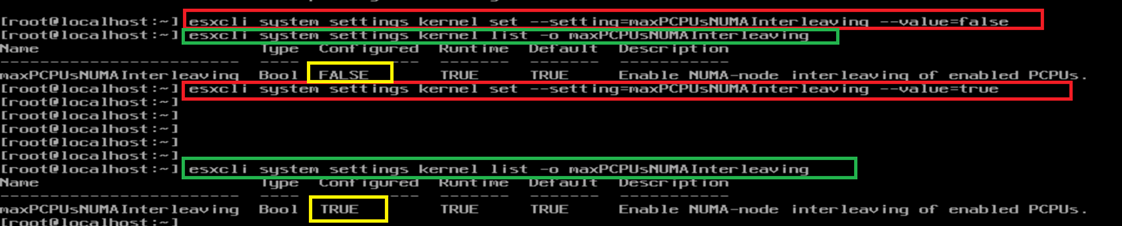
运行一下展示的命令
# esxcli system settings kernel set --setting=maxPCPUsNUMAInterleaving --value=true
此命令启用 NUMA 节点设置,该设置控制是否允许 NUMA 节点交错。设置为 true 时,将启用 NUMA 节点交错,这有助于改善某些工作负载的内存分配和性能。
相反,使用以下命令来禁用此设置。
# esxcli system settings kernel set --setting=maxPCPUsNUMAInterleaving --value=false
执行该命令后,通常需要重启主机以使更改生效。
要确定 NUMA 节点设置的当前状态,请运行以下命令。
# esxcli system settings kernel list -o maxPCPUsNUMAInterleaving
For Microsoft Windows
客户需要调用 Windows API 来更改 NUMA 配置。下面提供了一个 API 示例,介绍了如何迁移到多组节点亲和性,从而更改NUMA配置。
在使用 API 之前,请执行以下步骤以启用所需的注册表项:
1. 使用如下显示的 powershell 命令添加注册表项。
# reg add "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\NUMA" /v SplitLargeNodes /t REG_DWORD /d 1
2. 重新启动计算模块。 重启后这些更改将依然有效。
重要提示:对 Windows 注册表的不当编辑可能会导致意外错误。在进行任何更改之前,请先备份 Windows 注册表。
Example API
下面显示的示例需要 wdm.h 标头,该标头包含在 Windows 驱动程序工具包中。
//
// Resolution using KeQueryNodeActiveAffinity2.
//
USHORT CurrentIndex;
USHORT CurrentNode;
USHORT CurrentNodeAffinityCount;
USHORT HighestNodeNumber;
ULONG MaximumGroupCount;
PGROUP_AFFINITY NodeAffinityMasks;
ULONG ProcessorIndex;
PROCESSOR_NUMBER ProcessorNumber;
NTSTATUS Status;
MaximumGroupCount = KeQueryMaximumGroupCount();
NodeAffinityMasks = ExAllocatePool2(POOL_FLAG_PAGED,
sizeof(GROUP_AFFINITY) * MaximumGroupCount,
'tseT');
if (NodeAffinityMasks == NULL) {
return STATUS_NO_MEMORY;
}
HighestNodeNumber = KeQueryHighestNodeNumber();
for (CurrentNode = 0; CurrentNode <= HighestNodeNumber; CurrentNode += 1) {
Status = KeQueryNodeActiveAffinity2(CurrentNode,
NodeAffinityMasks,
MaximumGroupCount,
&CurrentNodeAffinityCount);
NT_ASSERT(NT_SUCCESS(Status));
for (CurrentIndex = 0; CurrentIndex < CurrentNodeAffinityCount; CurrentIndex += 1) {
CurrentAffinity = &NodeAffinityMasks[CurrentIndex];
while (CurrentAffinity->Mask != 0) {
ProcessorNumber.Group = CurrentAffinity.Group;
BitScanForward(&ProcessorNumber.Number, CurrentAffinity->Mask);
ProcessorIndex = KeGetProcessorIndexFromNumber(&ProcessorNumber);
ProcessorNodeContexts[ProcessorIndex] = NodeContexts[CurrentNode];
CurrentAffinity->Mask &= ~((KAFFINITY)1 << ProcessorNumber.Number);
}
}
}
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作