某局点CAS集群环境使用过程中一台主机出现重启的经验案例
- 0关注
- 0收藏 1956浏览

组网及说明
CAS版本: E0306
Onestor版本:0115
三个节点组成超融合的集群,中间使用交换机互联。
问题描述
一台主机出现重启现象,上面的虚拟机漂移到其他的主机上面。
过程分析
第一步:确定主机重启的具体时间点,可以通过查看虚拟机的迁移时间(一般虚拟机迁移时间和主机重启时间相近),也可以通过登录设备中通过uptime以及date命令确定主机重启的时间,使用当前的date时间减去uptime的时间,可以得出这台主机重启的时间点
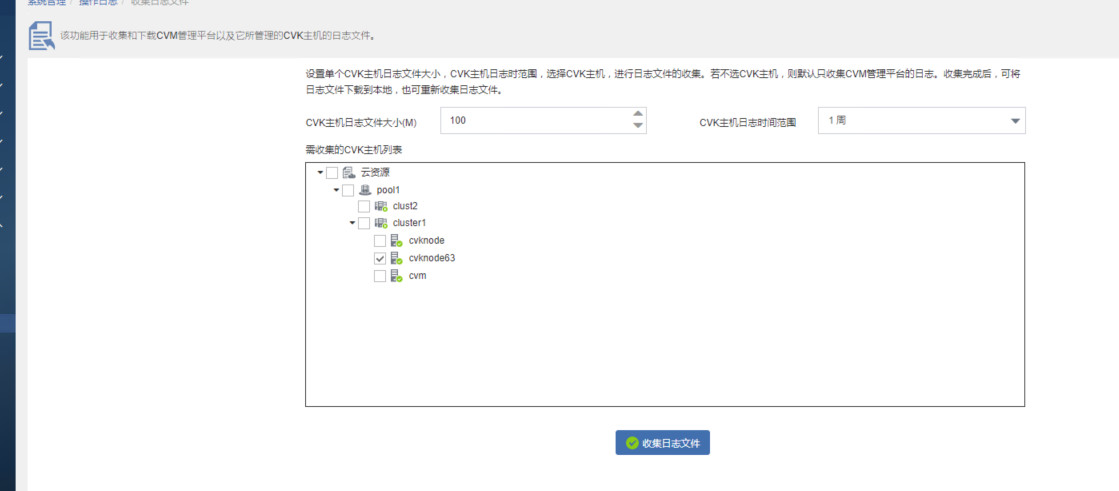
第二步:在CAS页面点击 系统管理--操作日志--日志文件收集,选中故障的主机,时间范围能包含重启的时间点,选中之后点击“收集日志文件”,将日志文件收集。
第三步:因为现场使用的是共享文件系统,CAS使用的共享文件系统是开源的OCFS2,OCFS2中有两种情况可能会导致主机重启:第一种是Heartbeat Dead Threshold,这个是主机与存储之间的心跳,目前CAS中此值设置为61,也就是主机与存储超时达到120S之后会出现主机重启;第二种是主机之间的心跳超时,也就是Network idle timeout,CAS默认是90S,也就是如果主机之前90S心跳不通,会根据重启算法将主机进行重启。重启算法的计算方法如下:使用同一共享存储的主机间心跳超时,分3种情况处理
主机数量为奇数
某主机无法连通的主机数量大于等于(total+1)/2,则该主机Fence,否则不重启。
比如节点A、B、C组成OCFS2集群,挂载了相同的存储池,如果节点B的管理网发生故障:则节点A或者B都可能发生fence,谁的编号大谁就重启。
主机数量为偶数
某主机无法连通的主机数量大于total/2,则该主机Fence
某主机无法连通的主机数量等于total/2,则集群编号为1或与1号连通的主机不Fence,否则Fence。
第四步:查看这台主机日志/var/log/ocfs2_fence_restart.log 日志,可以看到此主机出现了重启,原因为和其他节点的TCP未连接导致。
Restarted at 2019-11-06 17:11:25 (1573060285.935936). UNKOWN_DEV, UNKOWN_UUID, o2quo_make_decision: TCP disconnected with other nodes.
第五步:查看此时间的/var/log/syslog日志,可以看到重启之前,此主机和其他节点主机心跳网络超时,超过90S。进而导致导致主机重启
Nov 6 17:10:42 cvknode1 kernel: [41922516.530488] o2net: Connection to node cvknode3 (num 3) at 10.60.80.103:7100 has been idle for 90.112 secs. Nov 6 17:10:42 cvknode1 kernel: [41922516.530498] o2net_idle_timer 1596: Local and remote node is heartbeating, and try connect Nov 6 17:10:49 cvknode1 kernel: [41922523.704291] o2net: Connection to node cvknode2 (num 2) at 10.60.80.102:7100 has been idle for 90.112 secs.
Nov 6 17:11:25 cvknode1 kernel: [41922560.085641] (kworker/17:0,96609,17):o2quo_make_decision:212 ERROR: fencing this node because it is only connected to 1 nodes and 2 is needed to make a quorum out of 3 heartbeating nodes Nov 6 17:11:25 cvknode1 kernel: [41922560.085654] (kworker/17:0,96609,17):o2hb_stop_all_regions:2685 ERROR: stopping heartbeat on all active regions. Nov 6 17:11:25 cvknode1 kernel: [41922560.085660] *** ocfs2 is very sorry to be fencing this system by restarting *** Nov 6 17:11:25 cvknode1 kernel: [41922560.093149] ocfs2_restart file writting return 135
解决方法
因为主机之间的心跳报文走的是CAS的管理网络,所以需要保证管理网络稳定。
建议将管理网络设置为双链路聚合,增加网络稳定性。如果主机连接的交换机开启了生成树,则需要将此交换机连接主机的接口配置为生成树的边缘端口。用户设置之后未再出现主机重启的情况。
注意:
CAS使用共享存储环境中出现主机重启的情况,首先考虑是否是因为OCFS2导致。
OCFS2中有两种情况可能会导致主机重启:第一种是Heartbeat Dead Threshold,这个是主机与存储之间的心跳,目前CAS中此值设置为61,也就是主机与存储超时达到120S之后会出现主机重启;第二种是主机之间的心跳超时,也就是Network idle timeout,CAS默认是90S,也就是如果主机之前90S心跳不通,会根据重启算法将主机进行重启。重启算法的计算方法如下:使用同一共享存储的主机间心跳超时,分3种情况处理 主机数量为奇数 某主机无法连通的主机数量大于等于(total+1)/2,则该主机Fence,否则不重启。 比如节点A、B、C组成OCFS2集群,挂载了相同的存储池,如果节点B的管理网发生故障:则节点A或者B都可能发生fence,谁的编号大谁就重启。 主机数量为偶数 某主机无法连通的主机数量大于total/2,则该主机Fence 某主机无法连通的主机数量等于total/2,则集群编号为1或与1号连通的主机不Fence,否则Fence。
如果不是因为OCFS2导致可以查看主机中再/vms目录下是否存在kdump的日志,如果存在,可以收集此信息联系新华三工程师进行分析。
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作