CloudOS E5132告警内存超阈值
- 1关注
- 4收藏,2261浏览

问题描述:
您好:
如图所示,云平台上一直有这个一般报警,请问这种情况,我直接修改rc文件把限制内存调大就可以吗?
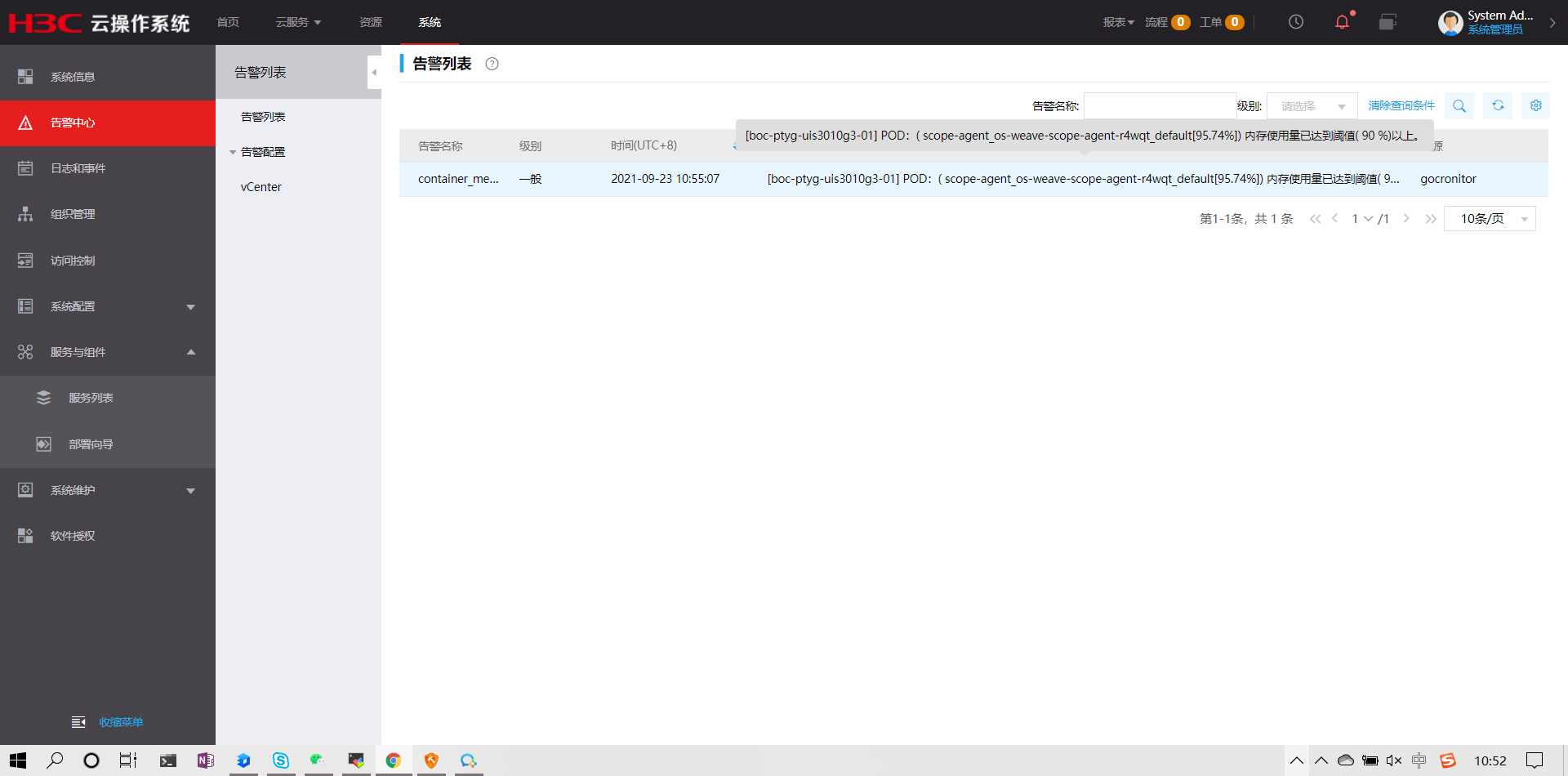
组网及组网描述:
- 2021-09-23提问
- 举报
-
(0)
最佳答案


docker ps | grep xxx
docker stats ID(ID是上一步获取到的)
- 2021-09-23回答
- 评论(2)
- 举报
-
(0)


您好,参考
待修复故障为某节点缓存使用量太高。

过程分析
在对应节点free -g查看内存使用情况,发现buff/cache使用量高达58G。该问题是由于内核的内存管理模块缺陷引起的缓存读写异常,除该告警外还会出现自动退出容器等问题。
[root@cloudosnode01 ~]# free -g
total used free shared buff/cache available
Mem: 125 59 7 4 58 57
解决方法
执行如下命令释放缓存。
echo 3 > /proc/sys/vm/drop_caches
看下这个案例是否能解决,也可以致电400工程师确认
NTP的问题,这个得实际看看设备得时间,如果不对也要修改。
- 2021-09-23回答
- 评论(0)
- 举报
-
(0)

咨询二线大佬后步骤整理,应该不具有普适性,最好还是拨打热线让大佬判断:
1、 kubectl edit deployment os-weave-scope-app 修改app的限制,内存和CPU都调整成了2倍
2、kubectl edit daemonset os-weave-scope-agent 修改app的限制,内存和CPU都调整成了2倍
3、kubectl delete pod os-weave-scope-agent-cm4bb os-weave-scope-agent-r4wqt os-weave-scope-agent-vn6bw 重启agent所有pod,默认修改app后其会自动重启,如果没自动重启需要先重启APP
等待一段时间之后观察CloudOS可以发现告警消失,分析产生原因是业务量较多导致资源使用较多产生告警
- 2021-10-12回答
- 评论(0)
- 举报
-
(1)
编辑答案


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作
举报
×
侵犯我的权益
×
侵犯了我企业的权益
×
- 1. 您举报的内容是什么?(请在邮件中列出您举报的内容和链接地址)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
- 3. 是哪家企业?(营业执照,单位登记证明等证件)
- 4. 您与该企业的关系是?(您是企业法人或被授权人,需提供企业委托授权书)
抄袭了我的内容
×
原文链接或出处
诽谤我
×
- 1. 您举报的内容以及侵犯了您什么权益?(请在邮件中列出您举报的内容、链接地址,并给出简短的说明)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
对根叔社区有害的内容
×
不规范转载
×
举报说明
请问如果确实mem已经90%以上,且反复出现,是进行扩容吗?