UIS超融合缓存盘异常
- 3关注
- 3收藏,2245浏览

问题描述:

目前业务正常 ,后台查看ceph -s 也是显示ok,这个要怎么处理
- 2024-01-16提问
- 举报
-
(0)

参考
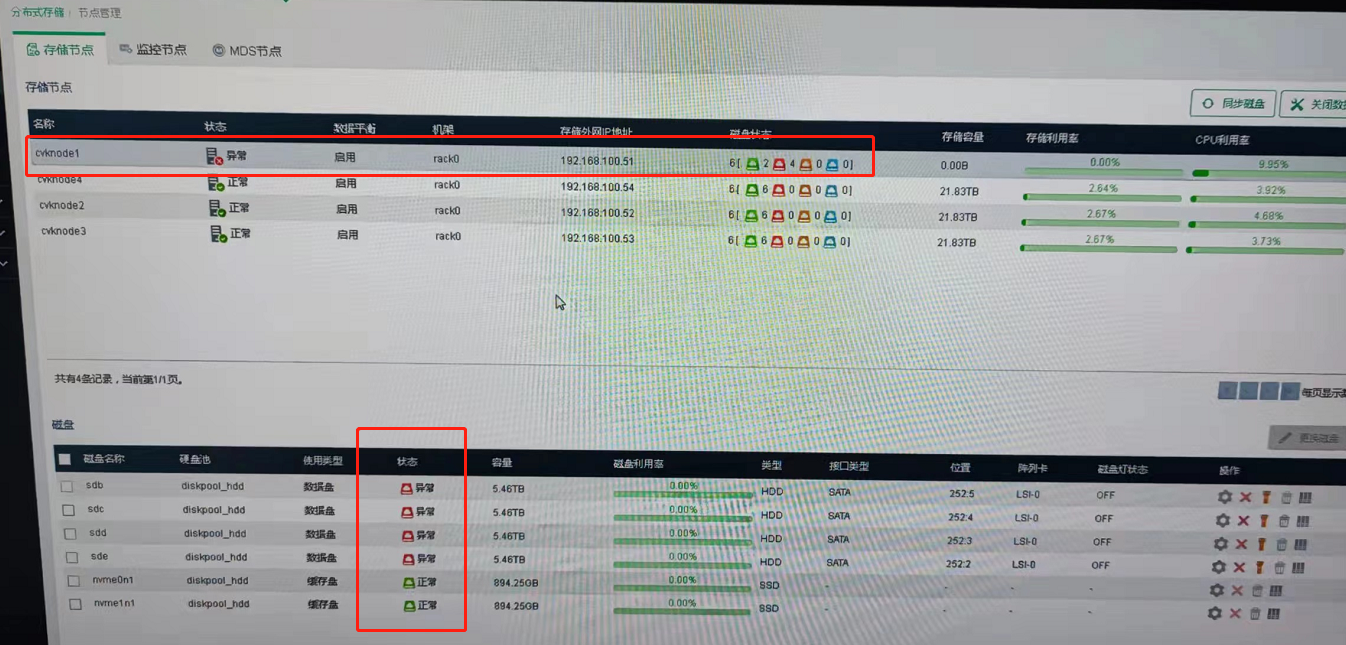
UIS E0750P02(ONEStor E3322),超融合部署,前台一个存储节点显示状态异常,该节点全部数据盘异常,缓存盘正常;
过程分析
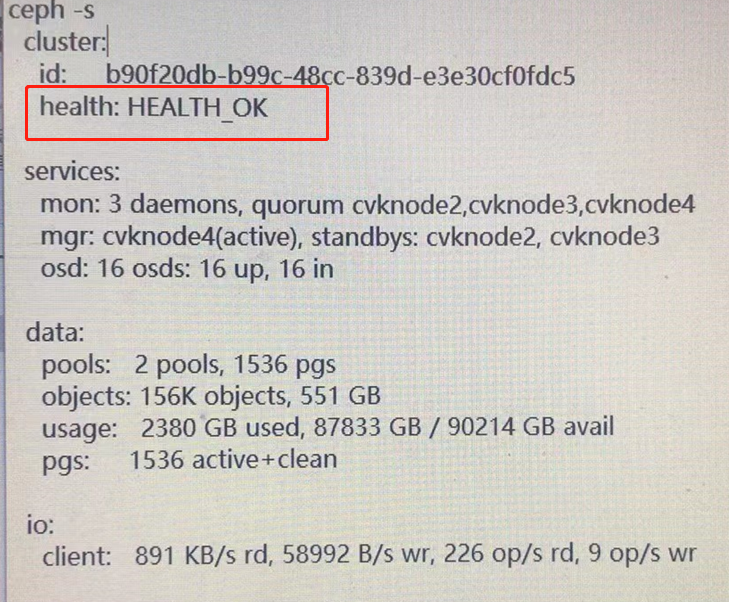
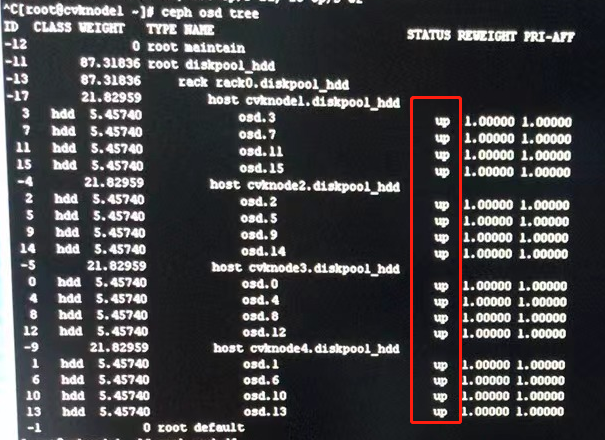
1、查看后台集群及osd监控状态;后台任一节点执行ceph -s查看发现集群是Health_OK ;再执行ceph osd tree 发现包括故障节点在内,所有osd 均为up;结合现场未反馈业务异常;判断应该是前台状态显示问题
2、清理浏览器缓存,尝试点击同步磁盘按钮,均无法恢复

3、故障节点后台执行top查看,发现onestor-peon进程占用cpu达到200%;
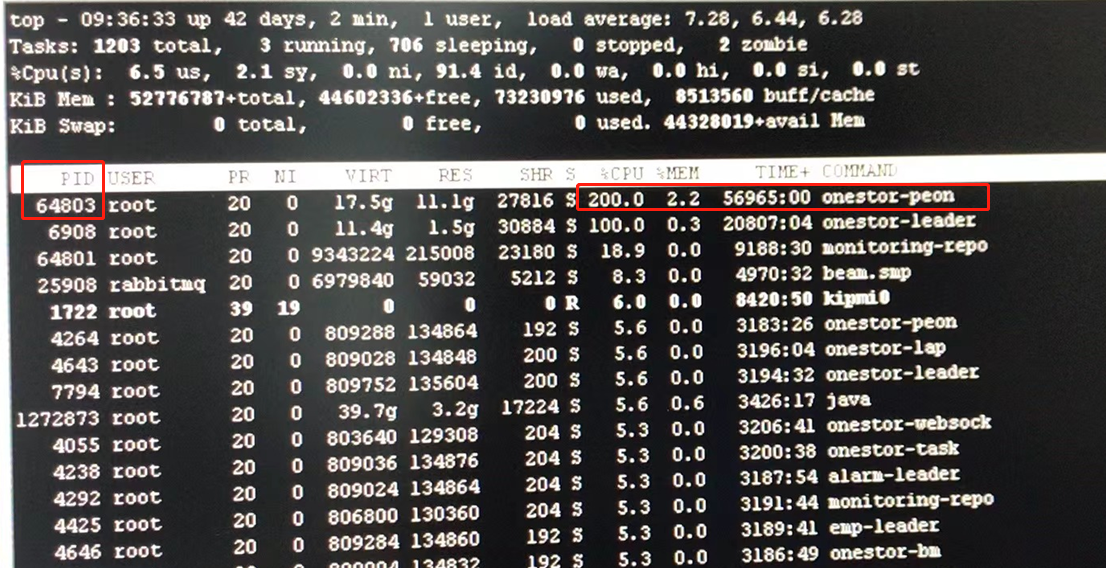
4、继续通过top -Hp [pid],其中pid为第3步查看到的onestor-peon的进程id,可以查看该进程的所有线程,发现其中有两个线程各占用CPU持续在99.9%;其中两个线程的pid分别为5731,71322
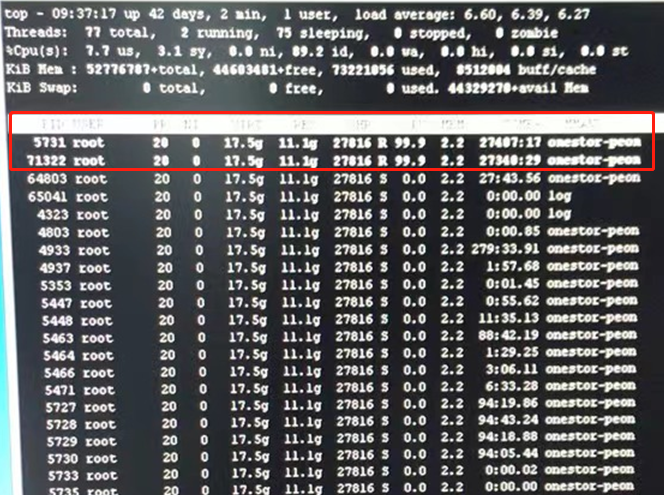
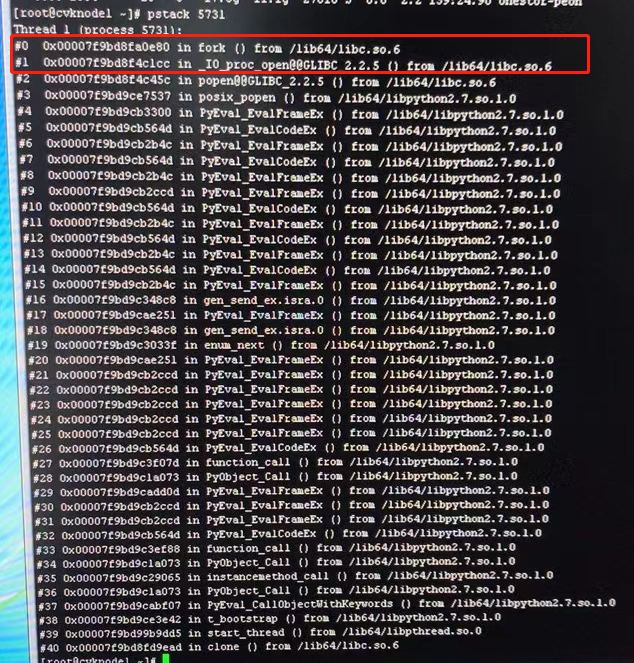
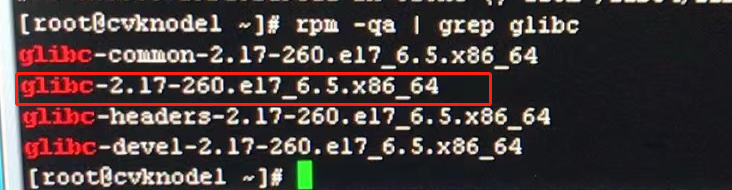
5、通过pstack [线程pid]查看线程的堆栈信息,发现glibc模块调用fork()异常;rpm -qa | grep glibc 查看glibc的版本为2-17.260,经确认,该问题为H3linux 操作系统 glibc模块的已知bug ;该模块调用fork()函数时概率性导致onestor-peon进程CPU利用率高,影响前台磁盘状态更新;
解决方法
临时规避措施:
在故障节点执行 supervisorctl restart onestor-peon重启该进程,前台清理缓存刷新后硬盘状态即可恢复;
彻底解决方案:
UIS需要在新版本合入H3linux的补丁,升级glibc版本后才能修复;当前暂无版本解决;
- 2024-01-16回答
- 评论(0)
- 举报
-
(1)
编辑答案


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作
举报
×
侵犯我的权益
×
侵犯了我企业的权益
×
- 1. 您举报的内容是什么?(请在邮件中列出您举报的内容和链接地址)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
- 3. 是哪家企业?(营业执照,单位登记证明等证件)
- 4. 您与该企业的关系是?(您是企业法人或被授权人,需提供企业委托授权书)
抄袭了我的内容
×
原文链接或出处
诽谤我
×
- 1. 您举报的内容以及侵犯了您什么权益?(请在邮件中列出您举报的内容、链接地址,并给出简短的说明)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
对根叔社区有害的内容
×
不规范转载
×
举报说明
暂无评论