问
uc一直有这个告警可以屏蔽吗
2026-01-28提问
- 0关注
- 0收藏,1489浏览

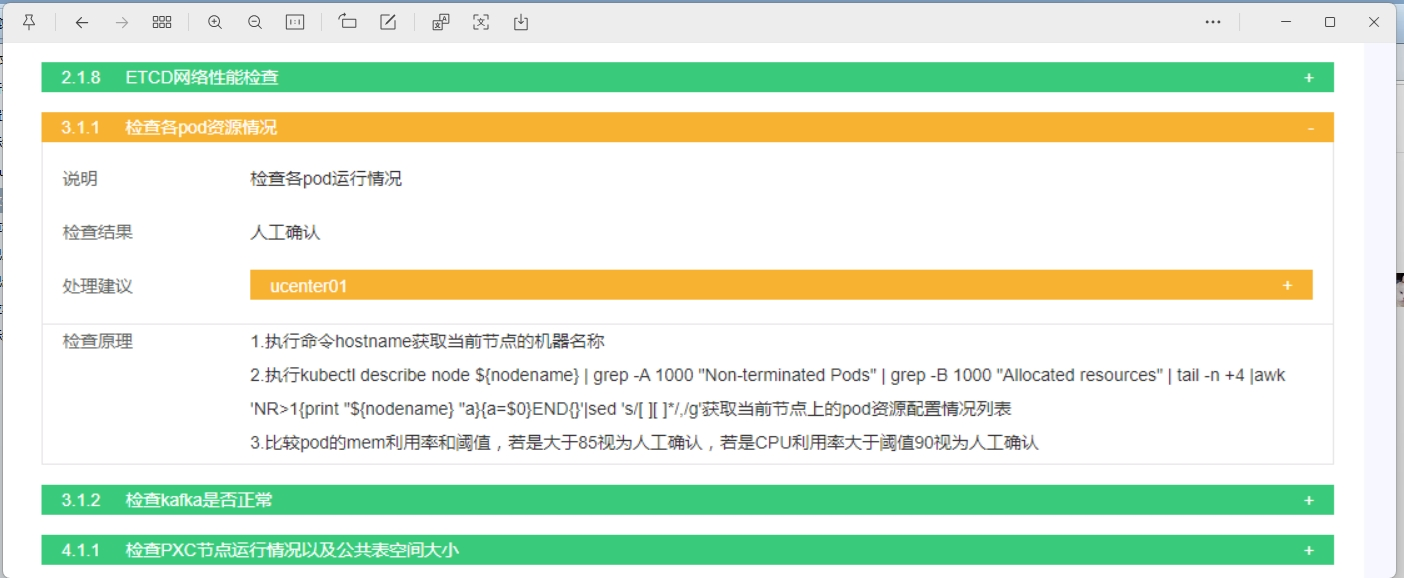


根据您提供的图片和描述,这个“人工确认”的告警绝不能直接屏蔽,而且必须要看。 这恰恰是监控系统最重要的预警功能之一。
为什么不能屏蔽?
- 这不是“故障”告警,而是“风险预警”:系统检测到某些Pod的资源使用率(CPU>90% 或 内存>85%)已经触及您设定的警戒线。它没有直接报“故障”,是因为Pod可能还在运行,但这是在告诉您:“资源快耗尽了,需要立即关注,否则下一秒就可能崩溃。”
- “一直有”才是最危险的情况:这恰恰说明了问题的严重性和持续性。这不是一次偶发的抖动,而是系统长期处于高负载或资源不足的状态,随时可能引发服务中断、性能下降等重大问题。
- “人工确认”的含义就是需要您介入:系统无法自动判断这是正常的业务高峰,还是异常的“内存泄漏”、“死循环”等程序问题,所以将决策权交给管理员。屏蔽它等于主动放弃了这道最重要的风险防线。
您应该怎么做?
立即行动,根据告警指引进行排查:
- 定位问题节点:处理建议明确指向
ucenter01 节点。您需要立刻登录这台服务器。 - 执行检查命令:按照图片“检查原理”中的命令,手动或在监控系统上执行,以获取详细信息:
# 获取节点上所有Pod的资源分配和使用情况 kubectl describe node ucenter01 | grep -A 1000 "Non-terminated Pods" | grep -B 1000 "Allocated resources" - 找到具体是哪个Pod:通过上述命令或以下命令,找出CPU或内存使用率最高的Pod:
# 查看节点上Pod的资源使用情况(需安装metrics-server) kubectl top pod -n <命名空间> --use-protocol-buffers | grep ucenter01 # 或查看所有命名空间的 kubectl top pod -A --use-protocol-buffers | grep ucenter01 - 分析原因并处理:
- 业务正常增长:如果该Pod业务量确实大,考虑增加其资源限制(Limits/Requests) 或扩容Pod副本数。
- 程序异常:如果资源使用率不合理,可能存在内存泄漏或代码效率问题,需要联系开发人员排查应用。
- 节点资源不足:如果该节点上很多Pod都资源紧张,考虑对节点进行扩容,或将部分Pod调度到其他节点。
后续优化建议
- 调整告警阈值:如果您确认当前85%/90%的阈值过于敏感,且业务峰值常态就是如此,可以与业务方确认后,谨慎地调整阈值(例如内存调到90%,CPU调到95%)。但前提是经过充分评估,确保有安全余量。
- 设置自动化处理:对于确认可自动处理的场景,可以考虑将“人工确认”升级为自动触发水平扩容(HPA) 的规则。
- 建立处理流程:将“人工确认”类告警纳入日常运维流程,明确负责人和排查步骤,避免遗漏。
总结来说,请立即查看
ucenter01节点的Pod资源状况。这个告警是系统健康的“晴雨表”,直接屏蔽等同于蒙上眼睛开车,一旦资源真正耗尽导致服务不可用,处理成本和影响将远大于现在花时间排查的成本。- 2026-01-28回答
- 评论(0)
- 举报
-
(0)

编辑答案
➤


✖
亲~登录后才可以操作哦!
确定
✖
✖
你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作
✖
举报
×
侵犯我的权益
>
对根叔社区有害的内容
>
辱骂、歧视、挑衅等(不友善)
侵犯我的权益
×
侵犯了我企业的权益
>
抄袭了我的内容
>
诽谤我
>
辱骂、歧视、挑衅等(不友善)
骚扰我
侵犯了我企业的权益
×
您好,当您发现根叔知了上有关于您企业的造谣与诽谤、商业侵权等内容时,您可以向根叔知了进行举报。 请您把以下内容通过邮件发送到 pub.zhiliao@h3c.com 邮箱,我们会在审核后尽快给您答复。
- 1. 您举报的内容是什么?(请在邮件中列出您举报的内容和链接地址)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
- 3. 是哪家企业?(营业执照,单位登记证明等证件)
- 4. 您与该企业的关系是?(您是企业法人或被授权人,需提供企业委托授权书)
我们认为知名企业应该坦然接受公众讨论,对于答案中不准确的部分,我们欢迎您以正式或非正式身份在根叔知了上进行澄清。
抄袭了我的内容
×
原文链接或出处
诽谤我
×
您好,当您发现根叔知了上有诽谤您的内容时,您可以向根叔知了进行举报。 请您把以下内容通过邮件发送到pub.zhiliao@h3c.com 邮箱,我们会尽快处理。
- 1. 您举报的内容以及侵犯了您什么权益?(请在邮件中列出您举报的内容、链接地址,并给出简短的说明)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
我们认为知名企业应该坦然接受公众讨论,对于答案中不准确的部分,我们欢迎您以正式或非正式身份在根叔知了上进行澄清。
对根叔社区有害的内容
×
垃圾广告信息
色情、暴力、血腥等违反法律法规的内容
政治敏感
不规范转载
>
辱骂、歧视、挑衅等(不友善)
骚扰我
诱导投票
不规范转载
×
举报说明
暂无评论