cloudos 告警信息提示证书到期,版本E5132,已确认无自动续签服务,手动续签方法有无遗漏?
- 0关注
- 0收藏,495浏览
问题描述:
分别用root权限登录三台服务器,手动更新步骤操作:
-
备份当前证书:为防止意外,请先进行备份。
cp -r /etc/origin/master/ /etc/origin/master_backup_$(date +%Y%m%d) -
执行手动续期:运行证书更新命令。
/usr/local/bin/cert-renewal -
重启相关服务:使新证书立即生效。
systemctl restart atomic-openshift-master-controllerssystemctl restart atomic-openshift-master-api -
验证证书有效期:确认证书已成功更新。
openssl x509 -in /etc/origin/master/master.server.crt -noout -dates -
(可选)故障排查:如果续期失败,可查阅日志文件获取详细信息。
和CAS之间有啥必要关联关系吗?cat /var/log/cert-renewal.log另外,想问一下,H3C CAS正常运行难道不能维持虚拟机集群正常运行吗?cloudos cloudos以及cloudos cloudos证书
- 2026-04-10提问
- 举报
-
(0)


你的手动续签操作步骤是完整的,步骤没有问题。在操作前,可以先确认下你的CloudOS版本是否支持自动续签。
CloudOS E5132版本默认开启了自动续签功能。证书会在到期前7天自动续签。
如果服务异常,你的手动续签方案是可靠的备选。另外,CAS授权与CloudOS证书是两套独立的体系,互不影响。
在执行手动续签前,建议用以下命令确认服务状态,判断是否真的需要人工介入。如果服务存在且处于active状态,系统到期前会自动处理,你就不需要操作了。
在CloudOS的管理节点执行以下命令:
# 2. 查看定时任务 systemctl list-timers | grep cert-renewal
结果判断:
均为
active状态,且定时任务存在:系统会自动续签,无需手动操作。服务未运行、报错或不存在:则确认你的手动续签方案是必要的。
如果确认必须手动续签,请按以下步骤操作:
备份当前证书:在所有节点上执行,以防万一。
cp -r /etc/origin/master /etc/origin/master_backup_$(date +%Y%m%d)执行续签命令:在所有节点上执行。
/usr/local/bin/cert-renewal重启相关服务:在所有节点上执行。
systemctl restart atomic-openshift-master-controllerssystemctl restart atomic-openshift-master-api验证证书有效期:在所有节点上执行,确认是否已成功更新。
openssl x509 -in /etc/origin/master/master.server.crt -noout -dates
如果续签失败,可以查看日志来排查原因:
它们关系明确,不是平级依赖。
定义不同:H3C CloudOS是云管理平台(负责“调度”),H3C CAS是虚拟化软件(负责“干活”),两者都内置了操作系统。
纳管关系:CloudOS可以纳管CAS(即一个CloudOS可以管理多个CAS集群),但CAS正常运行无需依赖CloudOS。
关键影响:CAS授权与CloudOS证书是两套独立体系。即使CloudOS的证书(或CAS的授权)过期,也不会互相导致对方的核心业务中断(如虚拟机停止运行)。只会分别影响各自的管理和运维操作。
- 2026-04-10回答
- 评论(0)
- 举报
-
(0)


手动续签步骤及易遗漏点:
1. 申请合规证书:需包含所有节点管理IP、集群虚IP、访问域名的SAN字段,私钥无加密、PEM格式,国密场景需备签名+加密双证书。
2. 前台用超级管理员登录,进入系统管理→安全管理→证书管理,删除过期证书后上传新证书+私钥,点击生效。
3. 必做补漏操作:
多集群场景同步更新子集群证书;前端有LB的同步更新LB上的访问证书;纳管的CAS/VCFC、对接的SSO/第三方平台同步更新CloudOS新根证书。
4. 验证:清浏览器缓存登录,确认证书有效期正常、告警消除、纳管资源对接无异常。
操作异常可回滚快照或恢复证书备份目录。
- 2026-04-10回答
- 评论(0)
- 举报
-
(0)
暂无评论
一、先给结论:你的手动续签步骤有遗漏,且存在关键风险点,同时明确 CloudOS 证书与 CAS 的关联关系
一、手动续签步骤的遗漏与优化(E5132 版本)
✅ 完整无遗漏的手动续签步骤(三台节点都要执行)
1. 【必做前置】备份(你已做,补充细节)
# 完整备份所有证书目录(不止master,还有节点证书)
cp -r /etc/origin/ /etc/origin_backup_$(date +%Y%m%d)
cp -r /var/lib/origin/ /var/lib/origin_backup_$(date +%Y%m%d)
# 备份etcd数据(核心!证书依赖etcd,防止续期失败恢复)
etcdctl backup -->$(date +%Y%m%d)
2. 【核心】执行证书更新(你已做,补充验证)
# 执行续期命令(E5132版本标准路径)
/usr/local/bin/cert-renewal
# 必须检查日志,确认无报错!(你已做,补充关键检查点)
cat /var/log/cert-renewal.log
# 日志中必须出现:All certificates renewed successfully 字样,否则续期失败
3. 【你遗漏的关键】重启所有相关服务(不止 master-api/controllers)
# 1. 控制面服务(你已做,补充顺序)
systemctl restart atomic-openshift-master-api atomic-openshift-master-controllers
# 2. 节点服务(遗漏!)
systemctl restart atomic-openshift-node
# 3. kubelet服务(遗漏!证书更新后kubelet必须重启)
systemctl restart kubelet
# 4. etcd服务(仅在master节点执行,防止脑裂,三台依次执行)
systemctl restart etcd
# 5. 路由/Ingress服务(遗漏!)
systemctl restart atomic-openshift-router
# 6. 监控/日志相关服务(遗漏!)
systemctl restart atomic-openshift-metrics-server prometheus
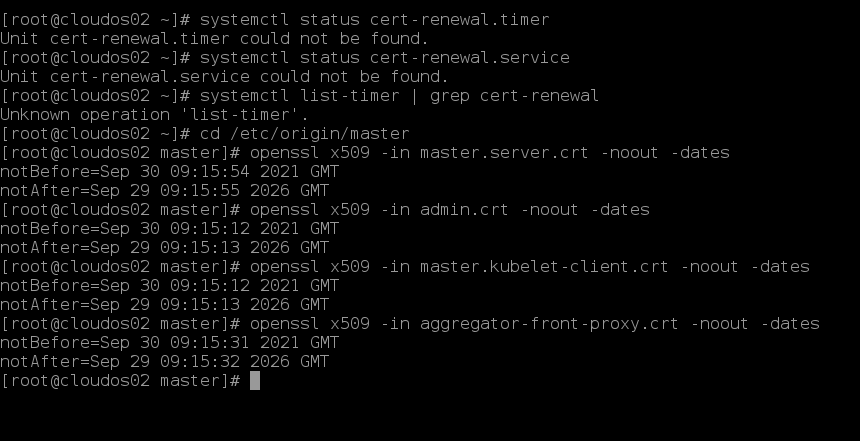
4. 【你遗漏的关键】验证全量证书有效期(不止 master.server.crt)
# 1. 控制面证书(你已做,补充完整)
openssl x509 -in /etc/origin/master/master.server.crt -noout -dates
openssl x509 -in /etc/origin/master/admin.crt -noout -dates
openssl x509 -in /etc/origin/master/master.kubelet-client.crt -noout -dates
openssl x509 -in /etc/origin/master/aggregator-front-proxy.crt -noout -dates
# 2. 节点证书(遗漏!)
openssl x509 -in /etc/origin/node/server.crt -noout -dates
# 3. kubelet客户端证书(遗漏!)
openssl x509 -in /etc/origin/node/kubelet-client-current.pem -noout -dates
# 4. etcd证书(遗漏!)
openssl x509 -in /etc/etcd/etcd-server.crt -noout -dates
# 5. 路由证书(遗漏!)
openssl x509 -in /etc/origin/router/default.crt -noout -dates
5. 【你遗漏的关键】验证服务状态与集群健康
# 1. 检查所有服务状态(确保无失败)
systemctl list-units --type=service | grep atomic-openshift
# 2. 检查集群健康(核心!)
oc get nodes # 所有节点状态应为Ready
oc get clusteroperators # 所有组件状态应为Available
# 3. 检查etcd健康
etcdctl cluster-health
6. 【你遗漏的关键】补全自动续签(解决根本问题)
cert-renewal.timer/service不存在,这是 E5132 版本的常见问题,手动补全定时器:# 1. 创建service文件
cat > /etc/systemd/system/cert-renewal.service << EOF
[Unit]
Description=CloudOS Certificate Renewal Service
[Service]
Type=oneshot
ExecStart=/usr/local/bin/cert-renewal
ExecStartPost=/bin/systemctl restart atomic-openshift-master-api atomic-openshift-master-controllers atomic-openshift-node kubelet etcd
[Install]
WantedBy=multi-user.target
EOF
# 2. 创建timer文件(每月1号凌晨2点执行)
cat > /etc/systemd/system/cert-renewal.timer << EOF
[Unit]
Description=Run cert-renewal monthly
[Timer]
OnCalendar=*-*-01 02:00:00
Persistent=true
[Install]
WantedBy=timers.target
EOF
# 3. 启用定时器
systemctl daemon-reload
systemctl enable --now cert-renewal.timer
# 验证定时器
systemctl list-timers | grep cert-renewal
二、CloudOS 证书与 CAS 的关联关系(核心问题解答)
1. 核心结论:CloudOS 证书到期,会直接影响 CAS 虚拟机集群的正常运行
| 证书类型 | 关联 CAS 的核心功能 | 证书到期后的影响 |
|---|---|---|
| CloudOS 控制面证书(master/server 等) | CAS 虚拟机的生命周期管理(创建 / 删除 / 迁移 / 快照)、资源调度、租户认证、API 接口 | 1. 无法通过 CloudOS 管理 CAS 虚拟机(控制台打不开、操作失败)2. 虚拟机无法正常开机 / 迁移 / HA 切换3. 租户登录 CloudOS 失败,无法访问云资源4. 严重时导致 CloudOS 集群崩溃,CAS 底层存储 / 网络调度失效 |
| CloudOS 节点 /etcd 证书 | CAS 的分布式存储(Ceph)、网络(SDN)、高可用(HA) | 1. 存储集群异常,虚拟机磁盘读写失败2. 网络策略失效,虚拟机网络不通3. HA/DRS 功能失效,虚拟机故障无法自动恢复 |
| CloudOS 路由 / Ingress 证书 | CAS 的 Web 控制台、API 访问、远程连接 | 1. CAS 管理页面无法访问2. 虚拟机远程桌面 / 控制台无法打开 |
2. 为什么 CAS “正常运行” 不能维持虚拟机集群?
- CAS 底层虚拟化(KVM / 存储)可以独立运行虚拟机,但所有管理、调度、高可用功能都依赖 CloudOS:
- 虚拟机的开机 / 关机 / 迁移 / HA,必须通过 CloudOS 的 API 下发指令
- 存储的扩容、快照、备份,依赖 CloudOS 的存储调度
- 租户的权限、认证、计费,完全由 CloudOS 控制
- 证书到期后,CloudOS 的所有 API 接口、服务通信都会被加密阻断,相当于 “管理中枢瘫痪”,底层 CAS 虚拟机虽然能临时运行,但无法进行任何管理操作,且随时可能因服务崩溃导致虚拟机宕机。
3. 关键补充:CloudOS 证书与 CAS 的绑定关系
- CloudOS E5132 是 CAS 7.0/8.0 版本的标配云管平台,二者是深度集成的:
- CloudOS 的证书直接用于 CAS 的 API 认证、服务间通信
- CAS 的所有管理功能(如虚拟机创建、存储管理)都必须通过 CloudOS 的认证
- 证书到期后,CAS 的管理平面完全失效,仅数据平面(虚拟机运行)临时可用
三、你的步骤遗漏总结(直接对照整改)
| 你当前的步骤 | 遗漏的关键环节 | 风险 |
|---|---|---|
| 仅备份 master 目录 | 未备份 etcd、node 证书、完整 origin 目录 | 续期失败无法恢复,导致集群崩溃 |
| 仅重启 master-api/controllers | 未重启 node、kubelet、etcd、router、metrics 服务 | 新证书不生效,服务通信异常 |
| 仅验证 master 证书 | 未验证 node、etcd、router、kubelet 证书 | 漏签证书,后续仍会告警到期 |
| 未补全自动续签定时器 | 下次到期仍会告警,需手动操作 | 重复故障,影响业务 |
| 未验证集群健康 | 未确认服务状态、etcd 健康、节点状态 | 隐性故障,后续业务中断 |
四、应急回滚方案(万一续期失败)
# 1. 恢复证书备份
cp -r /etc/origin_backup_$(date +%Y%m%d)/ /etc/origin/
cp -r /var/lib/origin_backup_$(date +%Y%m%d)/ /var/lib/origin/
# 2. 恢复etcd数据
etcdctl restore -->$(date +%Y%m%d)
# 3. 重启所有服务
systemctl restart atomic-openshift-master-api atomic-openshift-master-controllers atomic-openshift-node kubelet etcd atomic-openshift-router
五、最终建议
- 立即补全遗漏步骤:按完整流程重启所有服务、验证全量证书、补全自动续签定时器
- 三台节点依次操作:先操作一台 master,验证集群正常后,再操作另外两台,避免集群脑裂
- 升级版本(长期方案):E5132 已过生命周期,建议升级到 CloudOS E5300+,支持自动续签、证书管理更完善
- 监控证书有效期:配置 Zabbix/ Prometheus 监控证书到期时间,提前 30 天告警
- 2026-04-10回答
- 评论(0)
- 举报
-
(0)
暂无评论
编辑答案


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作
举报
×
侵犯我的权益
×
侵犯了我企业的权益
×
- 1. 您举报的内容是什么?(请在邮件中列出您举报的内容和链接地址)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
- 3. 是哪家企业?(营业执照,单位登记证明等证件)
- 4. 您与该企业的关系是?(您是企业法人或被授权人,需提供企业委托授权书)
抄袭了我的内容
×
原文链接或出处
诽谤我
×
- 1. 您举报的内容以及侵犯了您什么权益?(请在邮件中列出您举报的内容、链接地址,并给出简短的说明)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
对根叔社区有害的内容
×
不规范转载
×
举报说明
暂无评论