知
ONEStor3.0存在部分pg不一致场景,需要修复pg不一致问题
2021-12-23
发表
- 0关注
- 5收藏 2282浏览

组网及说明
ONEStor R2127等3.0版本
问题描述
现场ONEStor存储健康度异常,查看后台存储健康度存在如下pg不一致问题
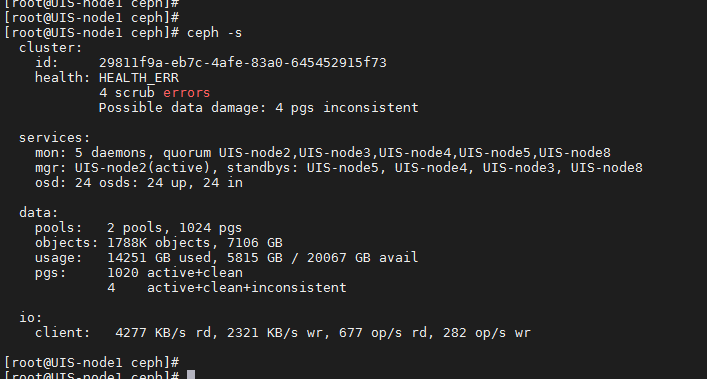
过程分析
查看后台osd tree,所有osd状态均正常,硬件层面无报错
解决方法
步骤1:提前关闭scrub和deep-scrub,任意节点执行:
ceph osd set noscrub
ceph osd set nodeep-scrub
步骤2:当没有pg在进行scrub和deep-scrub的时候,调整max_scrubs参数:
ceph tell osd.* injectargs --osd_max_scrubs=100
ceph tell mon.* injectargs --osd_max_scrubs=100
可以使用以下命令确认是否修改成功(X为执行命令的该节点所在的osd实际编号):
ceph daemon osd.X config show|grep max_scrubs
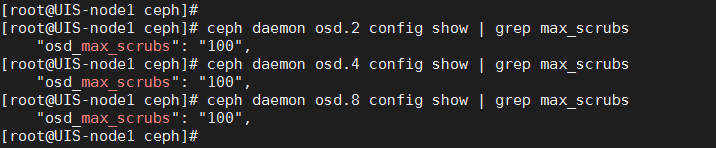
步骤3:根据ceph health detail 的输出找到需要修复的pg编号;
步骤4:执行修复命令:ceph pg repair PGID,且查看ceph –s有pg在进行repair
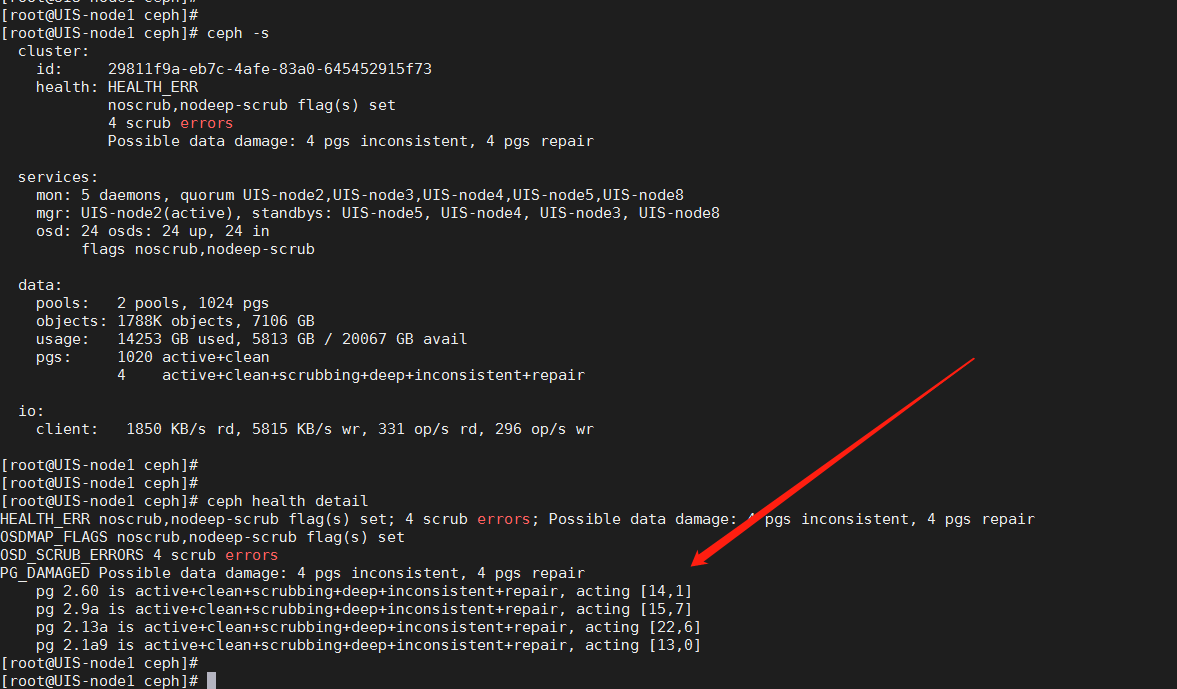
步骤5:等待pg修复完成,根据之前两个pg的修复情况可能会较长时间(2个小时以上)。
可以观察主osd的日志进行确认:
tailf /var/log/ceph/ceph-osd.X.log |grep fixed (当有fixed输出是表示修复成功)

步骤6:重复步骤3-步骤5修复其他pg,根据修复时间控制修复pg数量避免影响白天业务。
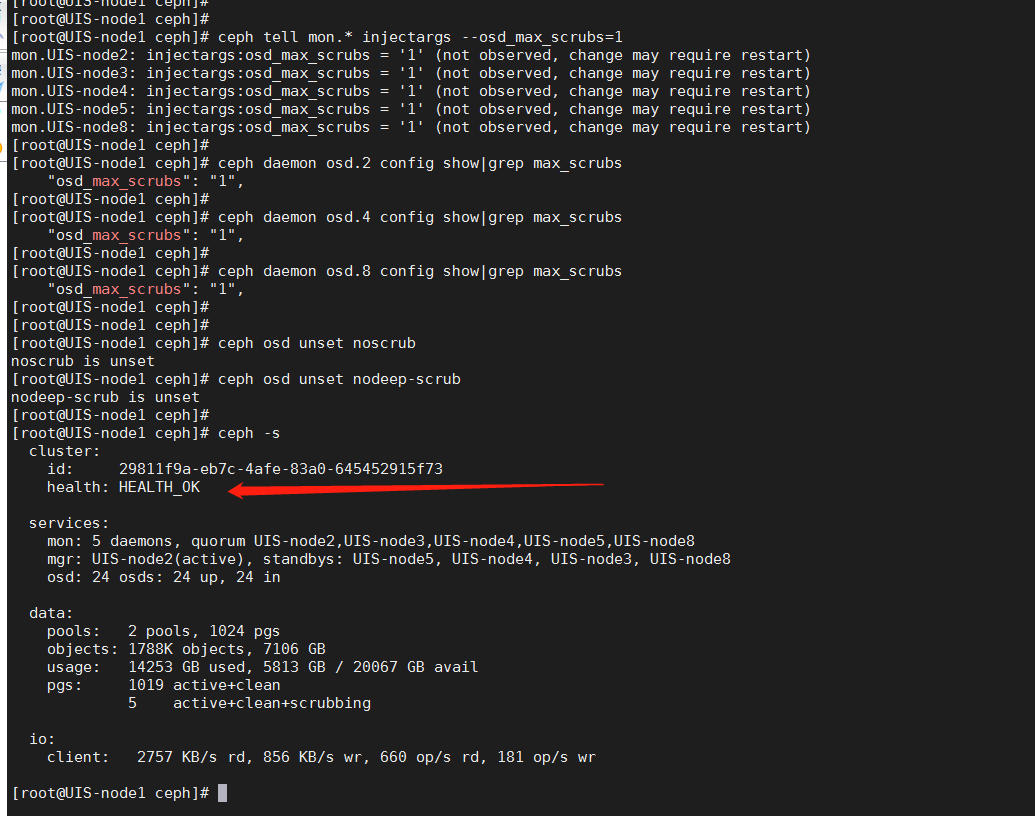
步骤7:结束修复之后将max_scrub值调回默认值:
ceph tell osd.* injectargs --osd_max_scrubs=1
ceph tell mon.* injectargs --osd_max_scrubs=1
可以使用以下命令确认是否修改成功:
ceph daemon osd.X config show|grep max_scrubs
步骤8:关开启scrub和deep-scrub,任意节点执行:
ceph osd unset noscrub
ceph osd unset nodeep-scrub
0
个评论
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈
➤


✖
亲~登录后才可以操作哦!
确定
✖
✖
你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作
✖