UIS 欧拉版本 GC不回收、回收太快等问题统一总结
- 1关注
- 5收藏 1806浏览

问题描述
本案例涵盖多个问题情景:
1.GC回收速度太快影响业务
2.UIS侧已经全部释放完毕,但是onestor侧仍然没触发GC回收,没有释放空间,如ceph osd df看盘的使用量很高,但是对应上层存储使用量很小
过程分析
一、针对GC回收过程做如下分析:
UIS 欧拉版本涉及到了GC回收,因此空间的释放分为多个层级
1.首先确定上层文件系统是否释放,如果上层都没释放,底层存储不可能进行释放:
tgt-admin -s 找到对应rbd块,然后查看此处的used量和df -h(或者前台存储池使用量)是否一致,如相差很大,说明是上层文件系统就没释放
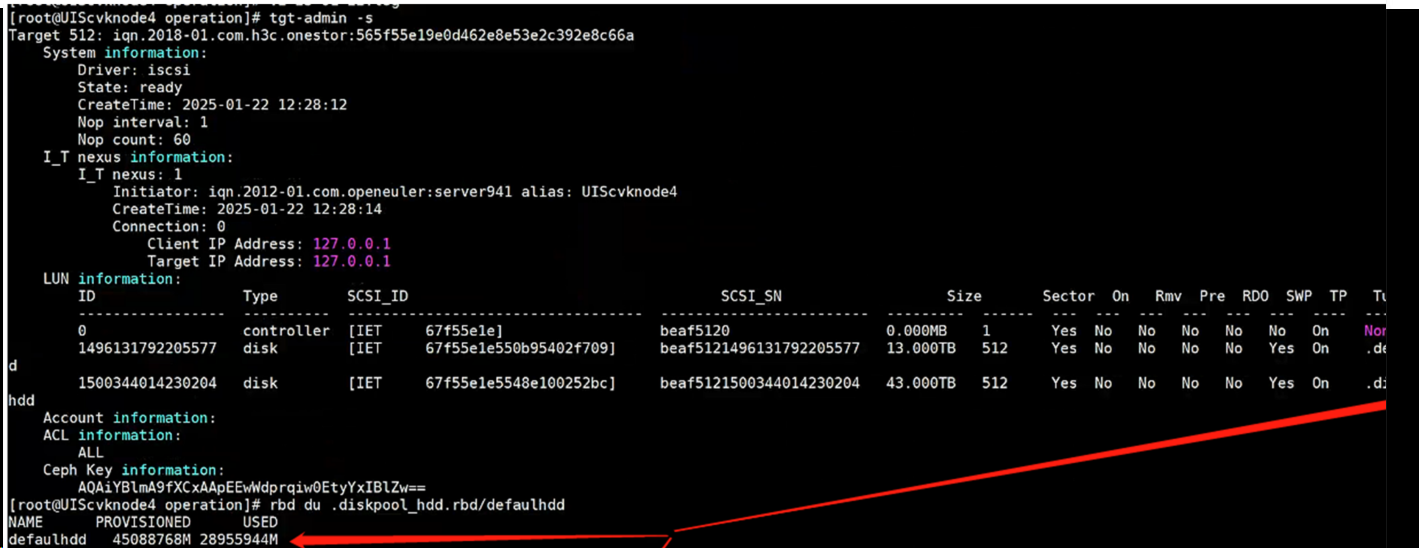
fstrim -v xxxxx进行上层文件系统的释放,尽量找到窗口按本指令或者按照fstrim文档操作,如果用本指令会占用一些IO,可能影响业务,此时释放的是块设备本身的容量。执行完毕会显示此次释放量的大小,再次rbd du xxxx查看,应该和df -h等一致
2.假如第一步查看都一致,或者已经按照第一步操作完毕,接下来可使用ceph df查看使用量,
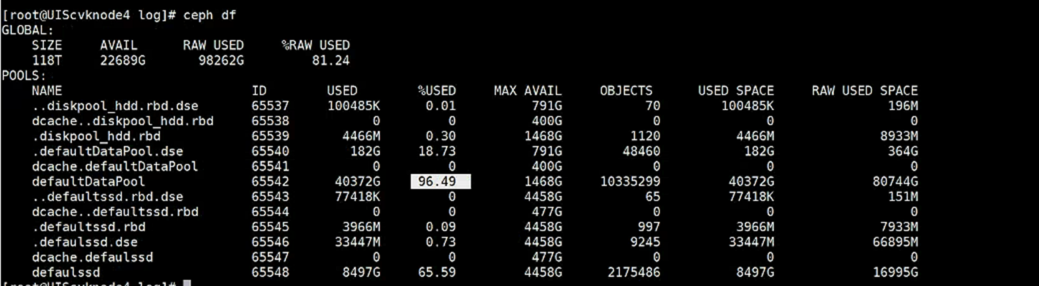 如果发现这里对不上,说明是onestor侧还未将其标记为垃圾,自然也不会触发GC的回收(onestor有定时任务做这个动作,如果着急释放可继续参考案例),需要手动去标记,所有存储节点执行如下指令(会占IO,可能影响业务,如果有窗口可以同时执行,不然建议一个一个节点来执行):
如果发现这里对不上,说明是onestor侧还未将其标记为垃圾,自然也不会触发GC的回收(onestor有定时任务做这个动作,如果着急释放可继续参考案例),需要手动去标记,所有存储节点执行如下指令(会占IO,可能影响业务,如果有窗口可以同时执行,不然建议一个一个节点来执行):
ceph daemon dse.`hostname` engine all full_compaction row
上述指令会标记垃圾,使得垃圾可视化的增多,同时可辅以本命令查看垃圾是否变得越来越多,这里的defaultDataPool换成现场的池:ceph engine get_osd_garbage defaultDataPool capacity,当垃圾确实增多后,会自动触发GC的回收,也会占IO,此时可再辅以watch ceph df查看使用量是否在下降,如下降,证明执行成功了
二、针对GC回收本身原理进行如下分析:
1.GC回收本身是针对对象而言的,对象本身包含了垃圾,有的对象含有垃圾多,有的对象含有垃圾少,因此onestor本身对垃圾进行了分级,含有垃圾多的对象就被分为了最先需要处理的,如bin_9,含有垃圾最少的对象则被划分到最靠后处理的,如bin_-2,具体可见下图:
输入指令:ceph daemon dse.`hostname` engine all gc dump | grep xxx -A 40 (这里xxx填写ceph df中看到的池子的对应的ID)
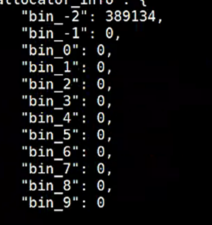
当存储池用的越多,就会越去释放上层的bin,比如存储用到90%,那么bin_0的垃圾也会进行回收,此时当然会影响到业务
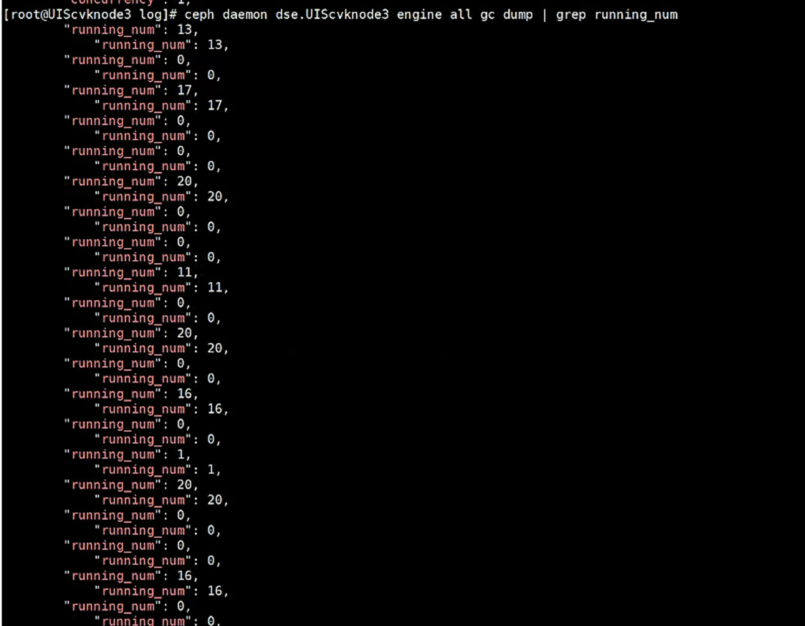
2.GC回收是有速度一说的,速度非常快的时候,占用IO就相当大,对业务影响极其大,可能使得虚机IO有几十秒的延迟,几乎是暂停了,那么我们如何确认是GC回收导致的问题呢?可以查看一下GC回收目前的速度:
ceph daemon dse.`hostname` engine all gc dump | grep running_num (其实也是基于上一条,查看running_num的数量,如882版本,是1-20之间,后面如886版本,是1-100之间,数字越大说明GC回收速度越高,下图为882的截图,达到17、20 说明GC回收相当快,占用了大量IO)
三、UIS侧已经释放完毕,但是ceph osd df看还是使用了很多,需要释放,但是GC也没有在回收,此时需要人为进行垃圾的扫描才可以触发GC的回收,进而使得osd的使用量降下来:
ceph daemon dse.`hostname` engine all full_compaction row (本指令需要在所有节点执行)
解决方法
由上对回收动作的分析,我们有两种解决办法,
一是直接降低GC的回收速度
watch -n 10 ceph daemon dse.‘hostmame’ engine all gc state set concurrency 4 (1-20,最高20,20对业务影响很大,单节点生效,这个是1-20等级的)
二是,直接从根本让不让GC回收,使得GC不回收多级的bin,人为“降低”存储池的使用率,当然此处不是真的降低,单纯是对GC的一种欺骗,在某个节点执行即可,全局生效(注意方法一的指令只对单节点生效!):
ceph engine force-start-pool-gc defaultDataPool 50 set (这个是欺骗GC,让她认为存储池使用率为50)
回退的办法是set改为unset
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作