知
磁盘性能不足导致etcd集群异常进而触发pod容器重启
2018-09-11
发表
- 0关注
- 0收藏 4286浏览

组网及说明
cloudos版本:E1138H01
问题描述
cloudos环境发现容器不定期重启
过程分析
1.分析pod容器重启原因:发现是Etcd无法及时向从节点发送心跳会导致集群状态不稳定,集群服务重启,进而导致Pod重启。
下图为集群主节点etcd服务的日志,可以看出心跳不能及时发送给从节点。
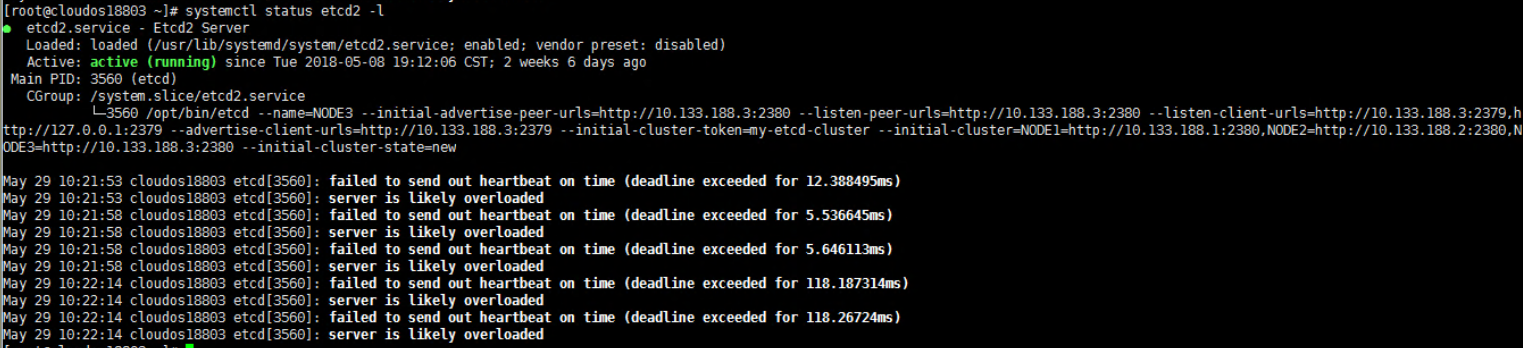
2.分析etcd异常原因:
Etcd的wal_fsync_durations指标用于标识ed对磁盘操作状态,官方给出的建议99%的延时应该少于10ms。
查看方法为:
l Web访问:ip:2379/metrics
l 命令行:curl ip:2379/metrics | grep fsync
下面三张图分别为三个节点上该指标的延时分布:输出显示延时极少落在16ms以内的,主要集中在32ms跟64ms之间,此外64~128ms、128~256ms、1~2s等区间均有分布,导致了集群状态的不稳定。



解决方法
问题定位在磁盘性能不足,造成etcd集群心跳超时,进而导致pod重启。所以处理方法:
1、缓解措施:
修改etcd超时时间,降低pod重启概率,但会增大集群间数据同步耗时增加,影响系统可靠性灵敏度,且随着业务量增加、系统长期运行磁盘损耗增大,pod重启概率会逐渐增加。
2、彻底解决:
更换RAID卡(缓存不小于1GB),提升磁盘性能。
0
个评论
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈
➤


✖
亲~登录后才可以操作哦!
确定
✖
✖
你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作
✖