virtual cores实际使用超过设置total参数导致Yarn任务卡住
- 0关注
- 0收藏 2172浏览

组网及说明
正常DE组网
问题描述
客户DataEngine大数据管理平台下发任务卡住,执行命令yarn application –list查看yarn任务发现任务进度条倒退的情况,比如增长到70%然后下降到5%再继续轮回。现场反馈一个任务基本需要两个小时左右,大概过上一天一夜所有任务都会被卡住。
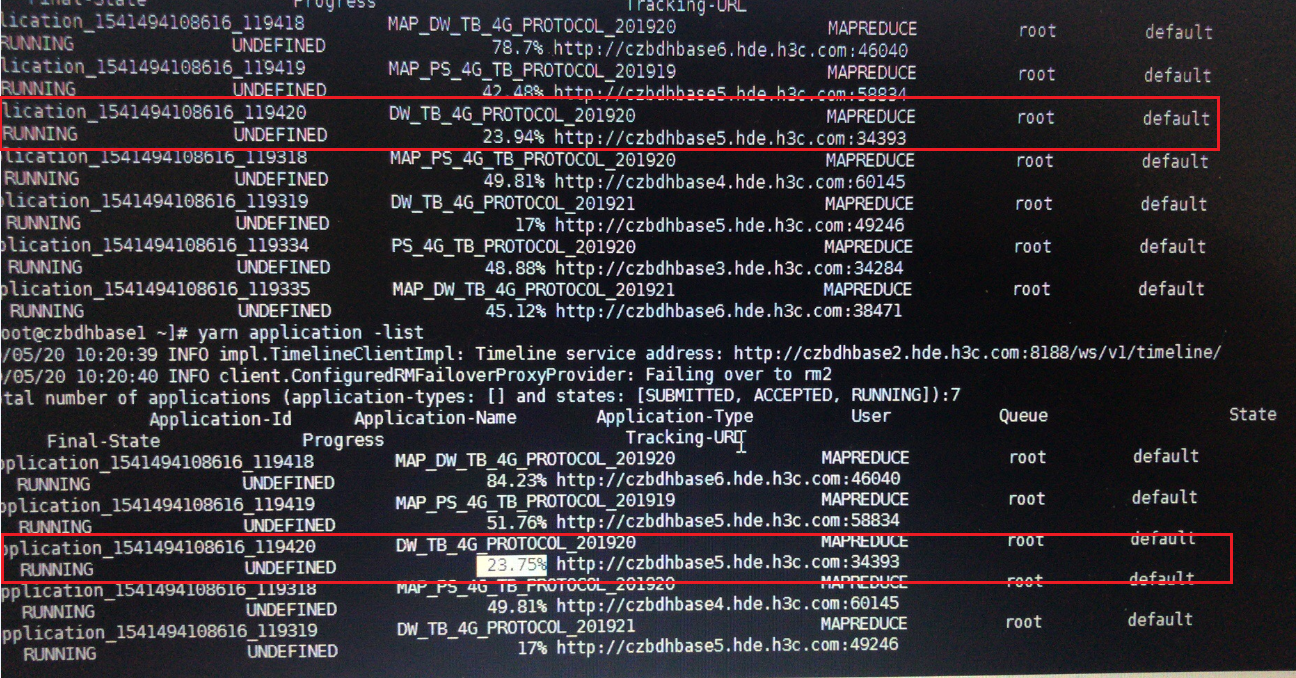
如下图所示任务,前面查询已经到23.94%,再查询进度下降到23.75%。
过程分析
1、了解现场业务情况:
了解现场提交处理的任务是bulkload把文件写到hbase。查看DataEngine管理平台各项服务状态都是正常的,查看磁盘利用率一直维持在80%左右。
点击快速链接进入ResourceManager UI管理界面查看资源任务情况。
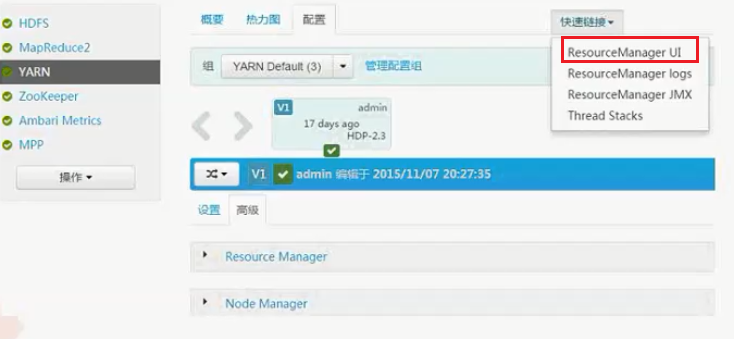
2、查看资源任务运行情况
在ResourceManager UI页面查看VCores Total是146,而VCores Used已经达到了180,VCores Reserved为0表示虚拟内核资源不足。对比验证其他普通业务(vcores和memory都在总资源内)运行正常。

解决方法
问题定位在业务所需资源超过Yarn总资源量。此时可以选择将集群资源增大或者控制任务提交数量。
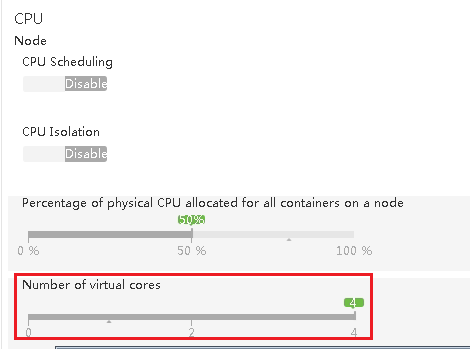
1、增大集群virtual core操作:
在Yarn“配置”下面的CPU部分,调整“Number of virtual cores”参数,然后保存、点击重启相应服务。
2、需要在提交任务的时候控制下map reduce的个数,减少map reduce负载。(其他计算组件类似。)
说明:对于Yarn任务卡住相关,第一先去UI页面查看各项资源是否有不足的情况,查看不出原因可以去看下Yarn日志。
该案例对您是否有帮助:
您的评价:1
若您有关于案例的建议,请反馈:
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作