ONEStor3.0中OSD对PG状态的影响
- 0关注
- 3收藏 2623浏览

组网及说明
1、实验环境
采用基于CAS 5.0 的虚拟机搭建ONEStor 3.0存储集群
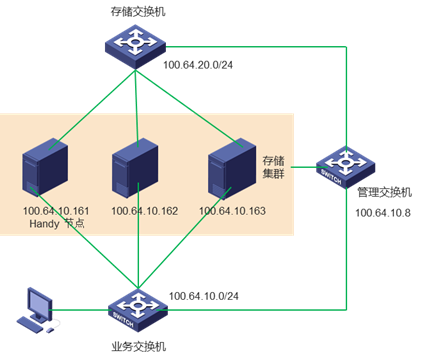
2、网络规划
管理网段: 100.64.10.0/24
存储前端网:100.64.20.0/24
存储后端网:100.64.20.0/24
3、集群部署
VM01 作为管理节点
副本策略选用3副本。
4、查看PG状态
ceph pg stat
5、查看pg组的映射信息
ceph pg dump 【all|summary|sum|delta|pools|osds|pgs|pgs_brief】
6、查看一个PG的map
ceph pg map 1.730
7、其他相关命令:
systemctl stop ceph-osd@3.service
umount /dev/sdc1 /var/lib/ceph/osd/ceph-3
systemctl start ceph-osd@3.service
mount /dev/sdc1 /var/lib/ceph/osd/ceph-3
ceph osd out osd.3
ceph osd in osd.3
ceph osd tree
问题描述
在实际环境中OSD的down状态和out状态会对PG的状态产生影响,本实验探究一下具体的影响。
过程分析
一、
1、down掉一个osd
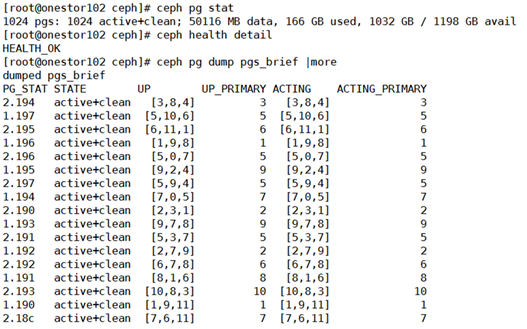
1)查看健康情况下的pg状态
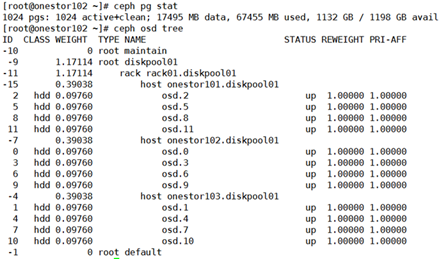
此时OSD均正常
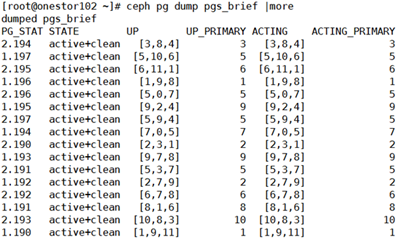
此时PG均正常
2)down掉一个osd进程后查看down掉一个osd后的pg状
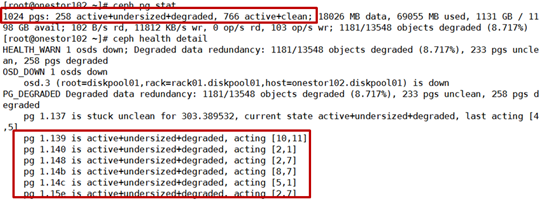
此时PG处于undersized+degraded状态,两副本
4)拉起osd查看pg状态
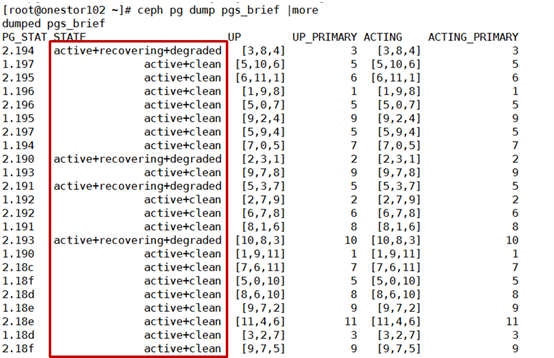
不正常的PG先处于recovering+degradeed状态,之后数据平衡处于正常状态。
2、out掉一个osd
1)out osd并查看pg状态
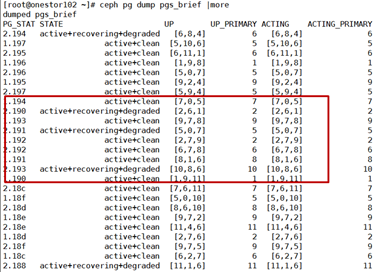
此时PG处于recovering+degradeed状态,三副本,之后数据平衡。
2)将out 掉的osd.3 重新拉回集群,查看此时PG状态
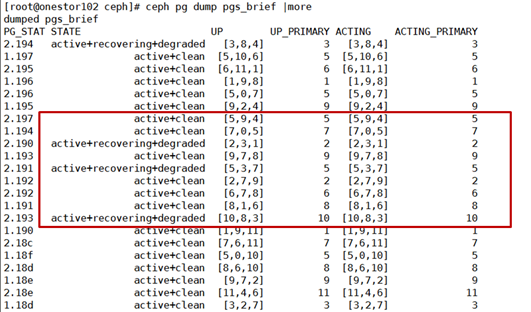
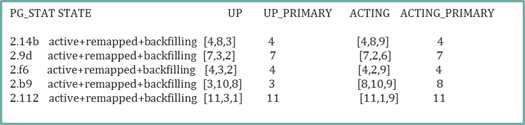
此时PG又处于recovering+degradeed或者remapped+backfilling状态,之后数据平衡,恢复原状态。
解决方法
down | down恢复 | out | out恢复 | |
PG状态 | active+clean—— active+degraded+undersized | active+recovering+degrade——active+clean | active+clean ——active+recovering+degrade——active+clean | active+clean ——active+recovering+degrade/active+remapped+backfilling——active+clean |
副本数 | 2 | 3 | 3 | 3 |
PG平衡 | 不触发 | 触发 | 触发 | 触发 |
集群健康度 | 不健康 | 100% | 100% | 100% |
映射关系 | 不增新osd | 恢复 | 增加新osd | 恢复 |
- 附件下载: PG概述及OSD对PG状态的影响.rar
- 2019-10-31 发表
- 举报
- 导出案例(pdf)
- 导出案例(word)
-
(2)
该案例对您是否有帮助:
您的评价:1
若您有关于案例的建议,请反馈:
该案例暂时没有网友评论
编辑评论
✖
案例意见反馈


亲~登录后才可以操作哦!
确定你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作