问
CloudOS有多个pod起不来,状态为ImagePullBackOff
2022-03-08提问
- 1关注
- 1收藏,2174浏览

问题描述:
CloudOS有CloudOS有多个pod起不来,状态为ImagePullBackOff,执行命令如下
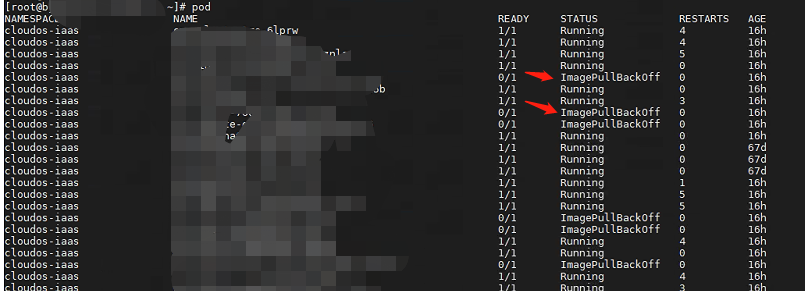


组网及组网描述:
- 2022-03-08提问
- 举报
-
(0)
最佳答案



您好,在CloudOS5.0环境中遇到与POD状态异常,不为Running时,可用如下方式进行排查
过程分析
1、查看该pod异常的具体描述
kubectl describe pod -n xxxxnamespace xxxxxx
查看其中的event事件说明
2、查看cloudos5.0数据库状态是否正常
pod |grep maxscale
kubectl exec -it os-maxcale-xxxxx maxadmin list servers
对应的三个mysql节点为os-mysql-node1、os-mysql-node2、os-mysql-node3
3、查看环境中所有的网络服务,包括业务网,pod网络
svc
oc get svc
4、查看节点etcd日志
master-logs etcd etcd |less
master-logs etcd etcd 2>&1|less
解决方法
default命名空间中的关键pod说明,这些pod异常时会导致其他pod异常
default redis几个pod比较关键,redisoperator负责维护自己的redis集群,redisproxy负责对外提供服务
当redis异常后一般通过重启方式恢复,重启整个redis集群,redis-0,redis-1,redis-2
另外三个redis-xxxx为redis的哨兵,负责redis主从确认
重启完redis集群之后再重启redisoperator和redisproxy两个pod,重启过程较慢,大概几分钟
- 2022-03-08回答
- 评论(0)
- 举报
-
(0)
暂无评论

编辑答案
➤


✖
亲~登录后才可以操作哦!
确定
✖
✖
你的邮箱还未认证,请认证邮箱或绑定手机后进行当前操作
✖
举报
×
侵犯我的权益
>
对根叔社区有害的内容
>
辱骂、歧视、挑衅等(不友善)
侵犯我的权益
×
侵犯了我企业的权益
>
抄袭了我的内容
>
诽谤我
>
辱骂、歧视、挑衅等(不友善)
骚扰我
侵犯了我企业的权益
×
您好,当您发现根叔知了上有关于您企业的造谣与诽谤、商业侵权等内容时,您可以向根叔知了进行举报。 请您把以下内容通过邮件发送到 pub.zhiliao@h3c.com 邮箱,我们会在审核后尽快给您答复。
- 1. 您举报的内容是什么?(请在邮件中列出您举报的内容和链接地址)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
- 3. 是哪家企业?(营业执照,单位登记证明等证件)
- 4. 您与该企业的关系是?(您是企业法人或被授权人,需提供企业委托授权书)
我们认为知名企业应该坦然接受公众讨论,对于答案中不准确的部分,我们欢迎您以正式或非正式身份在根叔知了上进行澄清。
抄袭了我的内容
×
原文链接或出处
诽谤我
×
您好,当您发现根叔知了上有诽谤您的内容时,您可以向根叔知了进行举报。 请您把以下内容通过邮件发送到pub.zhiliao@h3c.com 邮箱,我们会尽快处理。
- 1. 您举报的内容以及侵犯了您什么权益?(请在邮件中列出您举报的内容、链接地址,并给出简短的说明)
- 2. 您是谁?(身份证明材料,可以是身份证或护照等证件)
我们认为知名企业应该坦然接受公众讨论,对于答案中不准确的部分,我们欢迎您以正式或非正式身份在根叔知了上进行澄清。
对根叔社区有害的内容
×
垃圾广告信息
色情、暴力、血腥等违反法律法规的内容
政治敏感
不规范转载
>
辱骂、歧视、挑衅等(不友善)
骚扰我
诱导投票
不规范转载
×
举报说明
暂无评论